Introduction
Welcome to ‘The Future of Text’ Journal. This Journal serves as a monthly record of the activities of the Future Text Lab, in concert with the annual Future of Text Symposium and the annual ‘The Future of Text’ book series. We have published two volumes of ‘The Future of Text’† and this year we are starting with a new model where articles will first appear in this Journal over the year and will be collated into the third volume of the book. We expect this to continue going forward.
This Journal is distributed as a PDF which will open in any standard PDF viewer. If you choose to open it in our free Reader’ PDF viewer for macOS (download†), you will get useful extra interactions including these features enabled via embedded Visual-Meta:
- the ability to fold the journal text into an outline of headings.
- pop-up previews for citations/endnotes showing their content in situ.
- a Find, with text selected, locates all the occurrences of that text and collapses the document view to show only the matches, with each displayed in context.
- if the selected text has a Glossary entry, that entry will appear at the top of the screen.
- inclusion of Visual-Meta. See:
- In talks and discussions, the speaker’s name is notes
- : ‘ [speaker name]: … ’.
- Otherwise any other ad hoc bolding in the body text of articles should be treated as an editorial highlight.
- In some places URLs are deliberately placed on a separate line to ensure PDFprocess don’t break URL function.
- How can we model societal scale deliberation?
- How, in modelling societal scale deliberation, we can actually start creating ways in order to have more informed, inclusive, and unbiased decision-making?
- How can we generate policy more collaboratively by taking in the inputs of individuals? And then, ultimately:
- How can we have a common knowledge library on complex social and political issues that can inform the general public?
- it starts with archiving and collecting mass content,
- transcribing it and standardising it to text,
- extracting arguments,
- categorising those,
- clustering those into hierarchical categories,
- inputting that structured content into a database,
- and then tinkering with visualisation so that we can compress as much knowledge as possible in visualisations that can convey the complexity, without being way too overwhelming.
- When it comes to inputting content in the database, are we going to platform a dog whistle that we’re aware is a dog whistle?
- Are there going to be policies about trying to referee if one group is calling another group’s language a ‘dog whistle’ when, perhaps, it isn’t?
- Question nodes
- Category nodes
- Argument nodes
- We can create multi-premise arguments, unbelievably rigorous logical proofs.
- There are claim nodes.
- DefinitionsVariant phrases
- Videos
- Images
- Media
- Equations
- References
- Quotes
- And then, every single claim and node can have a pro, con, truth, relevance argumentation associated with that, as well.
- What should happen to the Diablo Canyon Nuclear Power Plant?
- And why is it being decommissioned?
- Direct manipulation
- Palm up for options
- Voice
- "Flip Walls" – the wall sizes version of the poster flipper above
- "Wall Carousel" – A giant rotating cylinder with different walls attached that you stand inside (or outside)
- Walls/workspaces that have a location inside a rotating or sliding "holder" so that they match our physical sense of place (spatial instead of hypertextual).
http://visual-meta.info to learn more about Visual-Meta.
Notes on style:
before their spoken passage marked thus
Frode Alexander Hegland & Mark Anderson Editors, with thanks to the Future Text Lab community: Adam Wern, Alan Laidlaw, Brandel Zachernuk, Fabien Benetou, Brendan Langen, Christopher Gutteridge, David De Roure, Dave Millard, Ismail Serageldin, Keith Martin, Mark Anderson, Peter Wasilko, Rafael Nepô and Vint Cerf.
Jamie Joyce: Guest Presentation
Transcript
Video: https://youtu.be/Puc5vzwp8IQ
Pre-Presentation
[Jamie Joyce]: Thanks again for having me, it’s really lovely to be speaking with all of you. Some of you I already know, which is pretty cool that you popped in today. And I just want to say also, I think it was Fabien and who was it, Carl? Was it you who mentioned future cities? And, Fabien, you mentioned VR interest? I got to say, I’m so fantastically interested in both of those things because at The Society Library, we’re extremely interested in researching different ways in which we can visualise knowledge. And I always can’t help but go to the VR space and think about how we can make inner direction much more multi-dimensional and even physical and kinetic. So I’m so excited about that, even though we're not working in that space, I want to get into that space. And then also, when it comes to Future Cities, The Society Library has also been recently working on creating decision-making models for city councils. So, I’m going to talk about our work in general and talking about all these different projects that we’re involved in. And if it’s not too gauche, I also have visual aids, and I can flip between screens to show you what everyone what I’m actually talking about if that’s all good with you.
Presentation
[Jamie Joyce]: Okay. In case any of you don’t know who we are, we are The Society Library†.
We’re non-profit, a collective intelligence non-profit. I’m going to start this presentation just by talking about who we are and what we do. Then I’m actually going to show you what we're up to. And I’d love to store some of your feedback and some of your ideas because some of you have been thinking about these types of projects for decades, and I’m only three years in. I have been thinking about it for about seven to ten, but I’m only three years in, in terms of implementing these things. So I’d love to get feedback and to hear how you think we could grow and expand what we do.
We’re The Society Library, the main projects that we’re working on are essentially:
All of these are very like pro-social, pro-democratic projects. The Society Library itself is attempting to fill a role in society. In the United States, we have something called the Congressional Revenue Service, it’s run by the Library of Congress. In the U.S., the Library of Congress actually prepares all of these lovely briefs and does all of this research for our members of Congress, our senators, and our house representatives. However, if I’m not mistaken, at the state and local level, as well as for the general public, these types of research services don’t exist. So our congresspeople, they can make a request to be brought up to speed on the topic of AGI and an entire library will work to organise and do all this research to deliver the knowledge products. And the Society Library is looking to do that for the general public, and also at the local and state level in government. So some of these projects that we work on are deliberation mapping projects, like our great American debate program, which I’ll talk about, specifically. We want to get into a project which we’ll probably rename because everyone hates it. I called it The Internet Government, people assume we’ve been governing the internet. We certainly do not mean that. It just means enabling governance platforms on the internet. So how can we generate policy? How can we produce decision-making models that are informed from the collective input and deliberation of? Essentially, what we’re aiming for is an entire nation. So we’re really working at the societal scale and I will talk about how we do that. And then, ultimately in our timeline, we want to fill this role as being accumulative common knowledge resource for the public. And so I’m going to talk about where we’re at right now, which is model and societal scale deliberations. And I’m going to get into how we actually go about accomplishing that.
Currently, the topics that we’ve worked on, that we’ve cut our teeth on, in the past few years have been the topic of nuclear energy, climate change, COVID-19, and election integrity issues. We’ve mapped a few other spaces, as well, essentially, associating actors with actions in political movements. So, for example, we were mapping these kinds of things out in the George Floyd protest. But what we’re really interested in is finding what are the fundamental questions that society has about specific issues. Currently, we’re working within the English-speaking United States. And then, can we go ahead and deconstruct the collective knowledge content that we have, to go about compiling answers to those questions so that we can compare, and contrast what propositions, what positions, what arguments have more or less evidence. What kind of evidence, how much evidence, produced at what time in corroboration with what. We’re really interested in just being able to start visualising the complexity of our social and political discourse. So that, again, it can, down that timeline, start forming decision-making models in the production of policy.
If it’s not obvious, to me what we discovered when we undertook the project of, Okay, let’s start mapping these debates is that, debates in the United States, on these high-impact persistent polarising issues, are actually unbelievably large. So the topic of climate change, I think we’re now up to 278 unique sub-topics of debate, and there can be tens of thousands of arguments and pieces of evidence in each one of those sub-topics. But interestingly, what we found is that all of these sub-topics correspond to answering only one of six questions. So all of these debates that are happening across various subjects related to conceptualising the problem of climate change and its severity, to solutions, and things like that, all of them are really responding to six fundamental questions.
Our latest subject that we’re working on is nuclear energy, and we’re still assessing what those fundamental questions are. For COVID-19, because it was such a new subject, and I think it was so global and so viral, we found over 500 and basically 13 fundamental questions. And for election integrity, there were 81 subtopics and two questions.
Today I’m also going to be showing you a project that we’re going to be releasing at the end of this month, which I’m really excited about. I’ll actually take you through the data structure and tell you more of what all of this actually means. I’ll show you questions, I’ll show you sub-topics, etc. So, how do we go about creating these debate maps? Which, again, I will show you what they actually look like towards the end.
We have this process that we’ve developed. Essentially:
claims and then evidence,
Something that we’re really interested in is: How do we create knowledge compression where people can see as much knowledge as they want to see and they have the flexibility to work in various dimensions to unpack what they want to explore as they want to explore it?
So instead of an author, who’s writing a book or a paper, taking a reader through a specific narration, instead it’s about: How can we visualise all the possible narrations that a reader can go through and they can unpack in the direction that they want to? And I think we’ve had a recent breakthrough in how we’re going to go about doing that in a really simple way, so I’m really excited about that. I’ll show you a tiny little sneak peek of it. But most of it is on wraps until we launch the project at the end this month if all goes according to plan.
So that’s the basic process, but let’s get specific because that kind of matters. So when we talk about archiving what do we mean? Well, first we built a bunch of custom search engines, to essentially, make sure that we’re pulling from all across the political spectrum and across different forms of media. We also have curated feeds that we keep an eye on. We are also aware that it’s really important to break the digital divide. There are just some things that people are not going to be willing to write a medium post about or post on Twitter about ideas that they have, that they do want to express. So, facilitating conversations and recording those interviews with permission, in order to gather that audio data is very important. We’ve also acquired access to various searchable databases, GDELT, and Internet Archive, which have just been absolutely wonderful to us.
One thing I do want to emphasise is that The Society Library takes very seriously our research methods. We have over 22 methods that we developed to try and counteract our own research biases. On our own echo chambers, we have a list of policies, also, on our website that talk about all the wicked problems of knowledge management that we’re seeing.
There’s all these wicked issues that we care very much about in addition to the methods that we’ve already deployed in order to overcome our own biases. And we’ve got a virtues and value page related to how we see ourselves in relation to knowledge. When it comes to us digging and scaring around, and archiving all this content, how do we feel about misinforming and disinforming content and things like that it’s, we like to approach our work with total intellectual humility, and those virtues and values are listed on our website. So we talk about that often in the culture of the Library, we often hire librarians who have their own code of ethics, which we also appreciate very much. The librarians in general, in the United States, take a very anti-censorship stance and instead argue that, if there’s the right context, any information can be interacted with to enable enlightenment. It’s not that some information should be hidden away, but what is the right context for knowledge to be experienced so that it informs and enlightens, rather than corrupts and persuades. So, we have developed our own code of ethics. We are also members of the ALA, so we adhered to those rules as well. I just love to say that. And then the process also begins by this, kind of, flyover, we call it, where we quickly find a whole massive topic, this can be done manually or computationally, where we just collect a bunch of topics across various media types, and we do that by specifically targeting and grabbing sample collection across different media types that contain certain keywords that are related to certain topics. If we’re mapping something related to nuclear energy and tritium leaking into the environment, which is a radiological hazard is one of those topics, our archivists and librarians are going to go through and find where does that keyword happen in podcasts, books, definitions, and government documents, etc, not only through time but also from news articles that are across the political spectrum. Once we have that diverse set, that’s when we do the next step, and let me just quickly say where we collect content from, scholarly, articles, research papers online, news, websites, blogs, social media, Twitter, recently Tik-Tok, Facebook and Reddit, we pull from documentaries, videos, and television, topics, specific community forums, and groups conference, videos and summaries, government publications and websites, existing FAQs and online resources. And then, we also conduct interviews with industry leaders, thought leaders, and experts.
And pro-tip, so many government agencies in the United States actually have in-house librarians and they are so helpful. We just send them our research questions like, “Hey, can you look through your entire agency’s library and help us find the relevant documentation?” And oftentimes they’re more than willing to help. So that’s just really lovely.
Anyway, once we grab the sample sets of data, we deconstruct all of that into text, we transcribe it, we translate it, we parse it, sometimes we even hire people to actually type up descriptions, text-based descriptions of videos, and graphic imagery, so we have that text, so it’s searchable. And then, once we have that content, what we do is, we start deconstructing the arguments, claims, and evidence. So we’ve got a training program for that. We have our own standards for what we mean by claim. Drive claim, implied claim, implicit claim, argument, etc. And I’m going to show you what deconstruction looks like just because it’s good to know what we’re talking about. So this is a transcript from a Sean Hannity† clip. It’s an old example, but it’s one of my favourite examples, because one of our favourite people at the Internet Archive asked us, specifically, to deconstruct this, because they couldn’t believe that Sean Hannity would make all these claims. I think this is only about like 17 minutes in length, yeah, it’s about 16 minutes and 20 seconds and all the claims that we were able to extract, I think, let’s see here, 100, oh, the implied ones are hidden away, so, in terms of directly derivable claims, Sean Hannity made 179 claims in his 17-minute snippet, and there was way more implied, I accidentally pulled up the wrong example, so sorry about that. I’m not an excel spreadsheet wiz, so I don’t know how to unlock the hidden implied claims. But anyway. From the exact transcript, which is right here, we actually pull out the arguments and claims directly, so oftentimes, you can see that there’s one line right here that can actually pull various claims from that. And that’s because language is complex. It’s dense. And we really want to extricate all of those tiny little fundamental units of reason, because we actually want to fact check it, qualify it, debunk it, ‘steel man’† it, devil’s advocacy, at all these things.
Another example I’d like to show, this is the Green New Deal. The Green New Deal is a famous legislation in the United States. When we’re training our students, because we have various educational internships, we’ve worked with 32 universities in the United States. One of the training projects the students do is, they deconstruct the Green New Deal to, kind of, get a handle on what the Society Library standard for clean is. So I think there are 438 claims in the Green New Deal. It’s a very short piece of legislation. If you just copy-paste it to a Google Doc, it’s like, 13 pages, I think, in a relatively big font. So it’s a relatively short documentation, yet, there’s 438 claims. And there’s very little evidence that’s usually provided in the legislation. It usually qualifies itself within like the… It actually does have an interesting structure. It’s a very complex argumentation. It has a premise where it says, “Congress fines given this document”. Which they reference the IPCC report if I’m not mistaken. These are our findings and our conclusion, which is the recommendations by congress to create a specific policy program or whatever. So, yeah. We deconstruct pretty far, I would say.
And then, going back to the presentation, what happens when we have all of these claims? That’s when we start categorising them. So these claims are going to have keywords, those keywords are going to be semantically related to other keywords. There’s ways in which, I hope in the future, we’re going to be better at computationally clustering these things together. I’m really interested not only in taking the data that we’ve created, using it as training data for claim mining, but I’d also like to start seeing if we can generate syllogisms just by the relationship between the keywords in text snippets. So that, potentially, with enough training, maybe our analysts would have more of a fact-checking role than constructing arguments from the base claims role.
But technically what we do is, we categorise cluster claims based on the relatedness to specific topics. So they may be, for example, on the topic of nuclear energy, it could have to do with grid reliability or stability, the tritium leakage, other radiological issues. We just cluster those into categories, and then from those categories, we’re able to derive different positions and more complex argumentative structures. I’m going to show you what some of that looks like in the debate map as we go on.
And I will say also that we’ve been very fortunate to have a very large tech company, who we’re not allowed to name, and a lovely university who we’re not allowed to name, who have made fantastic argument mining technologies, and they’ve given it to us to use. But we’re a small non-profit, so they’re like, “Yeah, don’t tell anyone we’ve done this”. So we also have interesting argument mining tools and we’re hoping that the training data we’re creating can make things even better. And this is just an example, again.
In this one natural language text snippet, we can pull all these claims.
A derivable claim means that we can, essentially, use the same language in the text snippet and just cut out some things and reconstitute it, in order to create claim.
When an implied claim is that you have to have some, sort of, insight into the meaning of the claim itself, which requires human intelligence in order to suggest that this claim would have to be a part of the argument, or one of the premises of the argument, in order for the claim to be proven to a certain extent, or made sound or valid.
So our analysts are also trying to put in implied claims but also mark them, so they don’t get confused with things that have been derived from evidence or from sources. That’s just an example of that.
And then, understanding our hierarchy is really important too. What we found is that if we just randomly choose a question, or randomly choose some dimension of a debate, what happens is, as we’re hand mapping the logical argumentation from that one point in the debate, we start to quickly get into a spaghettification problem. So we start having arguments that are somewhat relevant, it just, kind of, spiders out, and curls in on itself. It’s very messy. From what I’m told from people who’ve worked in AI for a long time, it’s called a good old-fashioned AI problem. But what we’ve discovered is, if we just do this kind of hierarchical clustering, over time, essentially, what we can do is have this descriptive emergent ontology that occurs. And what’s interesting is that the questions that are derived from finding the references and evidence, extracting arguments in the claims, organising those into those categories, and then, identifying those positions. In finding those questions, the questions, in turn, shape the relevance of what can be modelled in response to the question. So if we’re interested in having the most steel man formal deliberation possible, it’s the responsibility of our analysts to make sure that the positions are actually answering the question. So finding the questions that give shape to the relevance of the argumentation, which has really helped us to avoid that whole spaghettification problem. I don’t know if it solves that good old-fashioned AI problem in general, but it’s just something that has really helped us. We call it descriptive emergent structuring. And we’ve used it on all of our debates since we learned the first few tests that, just picking a random part of a debate isn’t going to work for us.
And then, we go ahead and map this content. We have a debate mapping tool. Every single week we ship new features and make it even better.
Some of the things that we can put into this debate mapping tool includes:
We can also, within every single node, have:
There’s ways in order for people to participate in calculating impact and veracity scores.
So we’re able to have a pretty complex argumentation that’s mapped out using this specific tool. And then, of course, we want to model it. And like I said, of the knowledge products that the Society Library produces, creating these maps is just one thing. We’re really interested in creating a much more accessible visual libraries apps. I would love to put it in VR, how fun would it be to stretch and open claims, to unpack them? It would be lovely. I would love to take some of our data and maybe work with someone who would have an interest in visualising these things. I think it could be lovely.
But the other things that we do, as I mentioned, we create decision-making models, so we’re moving into the smart city space. We’re trying to pitch it like, smart cities could be smarter if they had ways to augment their intelligence by externalising the decision-making process. Some of the work that we’ve already done, I mentioned earlier that, something that we’ve discovered in our work is when you really map a space, you find out how dense and complex it is.
So a city council wrote to us, and they asked us to help map a debate that they were having locally. And they thought it was a binary issue, like yes or no. And we found there were over 25 different dimensions of the decision that they were facing. And there were anywhere from two to five arguments with or without evidence in each one of those dimensions that they would consider. So we created a micro voting protocol that essentially allowed them to zero in on one dimension at a time. And the feedback that we got from that project was just so wonderful. People who felt like they were being marginalised, felt that they were heard. People who felt like they were on the fence, we were finally able to see that they were actually really certain of a specific position, they just need to externalise it.
So we’re moving in that space, and we’re pitching to various city councils to, essentially, not only do research work for them, like the Library of Congress does for congress, but also create these decision making models because that can increase transparency, accountability, and decision making, and it helps overcome a little bit of cognitive bias. Because if we’re making decisions in our heads, who knows what kind of black-box calculations and waiting is actually going on.
But if we’re forced to externalise it, and work with things one-on-one, and actually identify what dimensions we’re in agreement with, it just, I think, helps improve the process in some way at least a little bit. So we’re hoping that we can just improve decision-making in general.
And then, we’ve also been hired to create legislation. So using our method of deconstructing content down to the claim level, we produced federal level legislation. We essentially took hundreds of pages of congressional recommendations, broke them down to the claim level, and then, we compared those with legislation that was passed, failed, and pending at the state and federal level in order to, essentially, say, what, in the congressional recommendations, on this specific issue, is missing from the existing legal code at the federal level, and then, borrowing language from where it’s been attempted in the past, and produce a bill, just essentially, by claim matching, and filling in the blanks. So we were willing to work on something like this because it’s a very non-partisan issue. It had to do with the infrastructure bill. It had to do with the integrity of the electrical grid in the United States and recommendations to harden or make it more resilient. So it’s a totally non-partisan issue, we were happy to do it. And we also got amazing feedback from that work. We were able to, literally, deconstruct hundreds of pieces of legislation, and hundreds of pages of congressional recommendations in under three weeks, and deliver this proposal. So, most likely, we’ll continue doing non-partisan legislative work.
And then, also, we think that some of the data sets that we’re creating may actually be very useful training data, not just for us, but for other people as well. We’re thinking about that, also, being a potential revenue stream as a non-profit.
Oh, one more thing. I mentioned before that this debate mapping software has a lot of different features. We can pack videos, images, quotes, equations, references, and all these different things in a single node. And so, when we made a submission to the Future of Text book, it was about our concept of web-based conceptual portmanteau. I’m going to show you a little bit of what that looked like when we were initially mocking it up, and then by the end of this presentation, I’m going to show you where we’re at currently because I think it’s a huge improvement.
So our first foray into web-based conceptual portmanteau is, we were, essentially saying, portmanteau, when you combine a couple of words together, and it’s like this more complex meaningful word. And we’re like, “Okay, well, we’re trying to create portmanteau in terms of media assets. We want to combine references with images, videos, text and different variant phrases of the text, and all these different things”. So we mocked up this new node structure. And we were talking about different ways in which people could unpack and repack all of that knowledge. I’m going to show you our debate map and take you through a little bit, and then, I’ll show you the new version of web-based conceptual portmanteau, which is still being a little like tinkered with currently. I’m happy to show you a little bit of what we’re doing. So here’s an example of one of the debates that we’re going to be pushing out. This is the data staging area, so you’re very much seeing the behind-the-scenes. These are the tools that our data brains and librarians use to input structured knowledge.
I’m going to show you how complex it gets. So we were asked to map the deliberation about the Diablo Canyon Nuclear Power Plant in the United States. It’s the last one in California that’s in operation and there’s a great big debate about it. I think even Elon Musk has alluded to it in tweets. So it’s a high-profile issue for the state of California, and we were very lucky to be asked to start mapping it before it really blew up. What we’ve found so far is that there are generally like two fundamental questions that the community has which is:
I put little trophies as notes to myself so I don’t get lost. And so far what we found is there’s about seven different positions that the community is taking on these issues. And by community we mean academics from MIT, we mean the governor, we mean activists, we mean members of the local community. Essentially we had an interest in finding all the different stakeholders, checking out the media that they were producing, and then, extracting that media.
This data set, I believe is drawing knowledge from 880 different media artefacts. I have a list here. In this database, there are references to 52 knowledge from 51 scholarly articles, eight TV segments, 112 reports, five books and textbooks, 367 news and websites, 194 social media posts, 66 videos, 24 podcasts, 53 government international documents, together for 880.
And so far what we found is, there’s seven general conditions. One of those is that it should just be left to be decommissioned as scheduled. And then, we see that this breaks up into a variety of different categories. So there’s economic issues, environmental issues, safety and well-being issues, ethical issues, all in support of why it should be decommissioned to schedule. So, as we unpack this, we can actually start seeing some of the reasons that people pose for why it should be commissioned.
Diablo Canyon Nuclear Power Plant. Joyce, 2022.
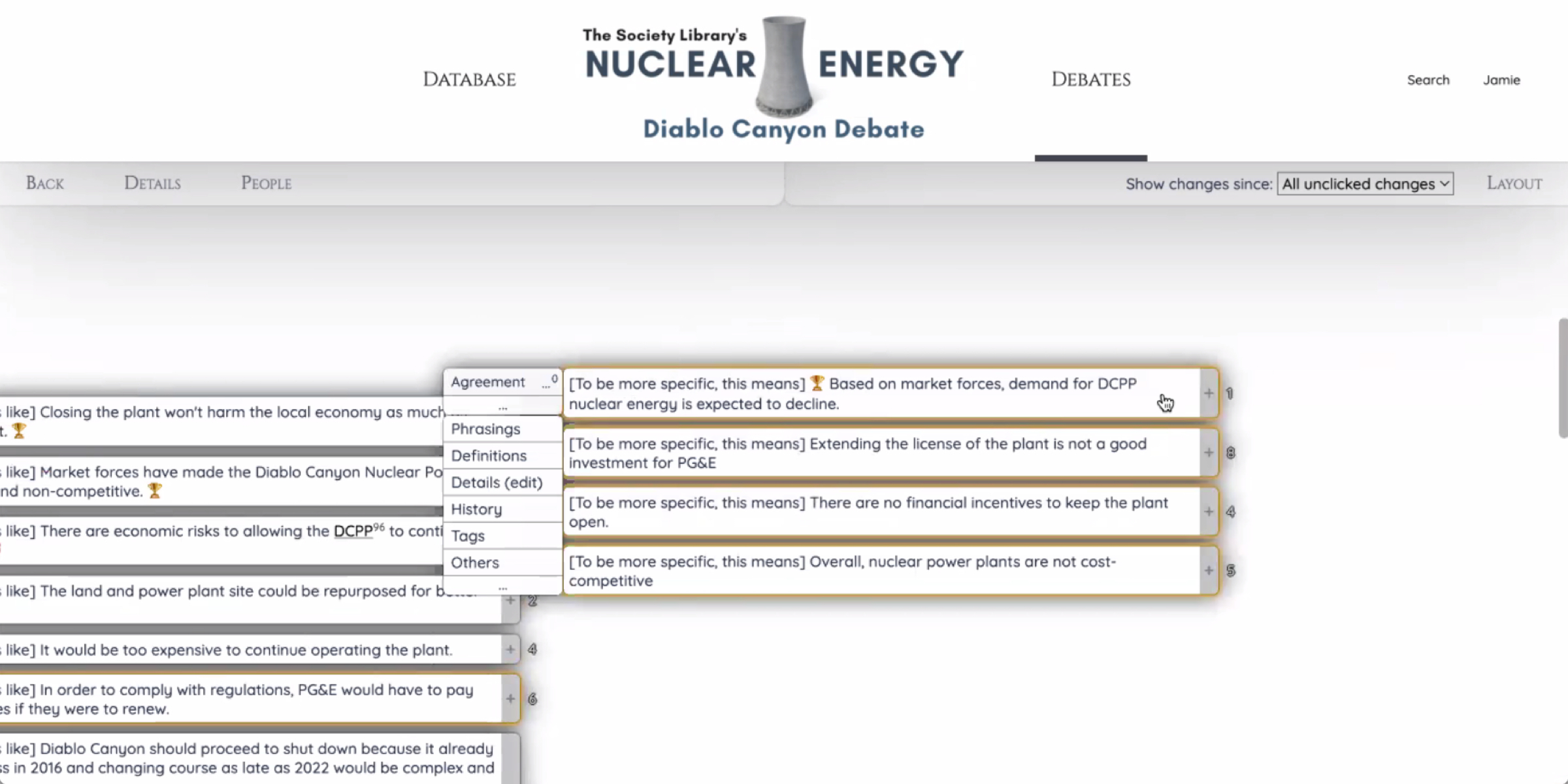
And you may notice that there’s these little brackets right here. Those brackets are important because, in order for us to translate data from this data set to the visualisations that we’ve created, we’re actually substituting these lines, which are indicators that the relationship between nodes with this language. So we’re doing this, even though we’re just creating this knowledge graph structure. And these lines, their colours, and orientation are indicators of their relationship. We actually will substitute with that language, so it’s completely readable (indistinct) visual.
Some of these claims in support of it being decommissioned that are related to economic issues include: that closing the plan won’t harm the local economy as much as previously thought, and that market forces have made the Diablo Canyon Nuclear Power Plant redundant and uncompetitive, so we can unpack this even more. And again, in brackets means that we’re essentially identifying the relationship between these tech snippets, other tech snippets, so as we move on from this one which won’t hurt the local economy as much as we thought, the economic impact of the local economy would be smaller than previous estimates in part due to economic resources that we made available, and over time, the region will overcome economically and experience positive growth. Now I’m just going to take a moment to start unpacking a little bit of what’s available in this node. So what you’re seeing is this text and these references here. What we also actually have is a bunch of different phrases, a bunch of different ways of expressing the exact same point in a similar linguistic register. So we’ve identified that as standard. We also want to make all of these nodes really accessible to people with less subject matter familiarity and can handle less cognitive complexity. So this simple version uses much more simple vocabulary. It says, even though it seems like there will be a lot of bad economic consequences when it closes down, some experts think it won’t be that bad. So it’s a very simple way of expressing the same thing. And we have some more technical versions of this claim that actually refer to the economic assessment. Why that assessment was commissioned? What type of specific input-output modelling tool was used to derive those conclusions? It’s a much more technical way of expressing that same claim. And then, in support of this particular claim, we have a multi-press right here which actually breaks, this is the summary of the multi premise which we can unpack here that actually breaks down the logical argumentation that led to this particular conclusion. So every single stage of, not the experimentation but the conclusion, so the first step of the decommissioning process will result in this kind of economic growth, and we’ll have economic losses, then we’ll have economic benefits. Overall it will conclude that. And this can unpack even further because each one of these premises in this argument can also have pro/con argumentation that can argue whether it’s true, support it, or its relevance. We have an example of a relevance argument here, which calls out that the economic impact assessment didn’t look at the economic impact after the decommissioning of the plant was complete. So when it talked about positive economic growth, it was only so far out of a projection and they didn’t include certain things in their model. And, of course, this comes from news articles. So it’s about collaboratively finding where the conversation is happening, distributed across different media artefacts, and then bringing that argumentation actually close together in one spot for people to explore. I’ll show another little example and there’s tons of these. Based on market forces demand for CCP nuclear energy is expected to decline. We have another multi-press here which essentially breaks down all of the different economic trends that are happening, which have been collaboratively expressed. So it’s not just that energy efficiency policies are going to reduce overall electricity consumption, there’s also increased solar then CCAs also don’t prefer to buy nuclear energy. And as you can see, it can get pretty dense pretty quickly because all of these are unique arguments that support these more vague generalisable premises. So the more that we go upstream and go left, the more vague the statements are, and the more interested someone is in to, actually, digging into the argumentation and evidence that’s available to support these vaguer, high level, commonly expressed sentiments, people can really dive in deep and explore.
But of course, this begs the question: Why on earth would anyone do this or want to find knowledge organised this way?
And even though when we publish this collection, we’re going to have a viewable version of this map accessible if people love to explore this map. Hopefully, we’ll deal with the functionality a little bit, we will centre things and make it a little bit better. But we know that this isn’t really going to cut it, in terms of making this accessible, legible, etc. So what I’m really excited about, going back to the web-based conceptual portmanteau, we’ve been wondering, how can we take all of this knowledge and really compress it down? So I’m going to show you a sneak peek, I wasn’t originally going to show up because this is recorded and I didn’t want this to end up on YouTube yet, so I’m just going to show you one image and just give you a little taste of it.

Society Library papers. Joyce, 2022.
This is what we call Society Library papers. This is just the design mock-up, we’re building it right now. But we’ve figured out a lot of different features that I’m really excited about, and we’re hopefully going to have more time to test it and make sure that it’s actually as visible as we think it is. Actually, a lot of knowledge can be compressed in a paper, and what we’re doing is actually allowing the paper itself to unpack in different dimensions. And by clicking on different snippets, each one of these are arguments. It can open up different screens where people can view the variant phrases and things like that. So we’re going to drastically simplify and compress a lot of this knowledge while maintaining all of the complexity. But making it more of like a bulleted outline that opens up and closes back up as people want to dive in deep to each one of these sections. And we want to have ways in which people can track how much of it they’ve seen, etc. There are other ways, in which, we’re thinking about visualising content too. But that still needs to be flashed out more before I’m excited to share it. Although there are things I really think, just like we are figuring out all the ways in which we can have all the complexity and features of this debate map in a piece of paper, I think we’ll be able to do the same with video, and if some magical VR magician comes by and wants to take this data and start changing visualisations as well, I think experimenting with it in VR, is going to be very important for us as well. So I think those are all my tabs that I had an interest in showing you all. And 45 minutes in, wow, I think it’s a good time to pause and ask:
You all have been thinking about these issues longer than we have, what should we be learning? What have we missed? Who should we be learning from? Would love your feedback. And thank you all for your attention and time, too.
Dialogue
https://youtu.be/Puc5vzwp8IQ?t=2030
[Frode Hegland]: Yeah, thank you. That was intense, and our wonderful human transcriber is going to work overtime on your presentation. Danillo, he is very good, so it’ll be fine. I’m going to start with the worst question just to get that out of the way and that is: You’re American, we’re British. You had Trump, we have Boris Johnson. It seems a lot of that politics is just personality-based, “Oh, I like him”. Or some kind of statement like that. Where would you fit that in here? Or do you consider that, for this, out of scope?
[Jamie Joyce]: To a certain extent, I think there are certain things that are relevant, and some of it is out of scope. So, one thing I just want to acknowledge is that I think we’re in the middle of an epistemic movement. So there are a lot of people who are working on different dimensions of how can we have an epistemic revolution? I like to call it the e-Lightenment. So how can we use new technology to transform our relationship with information?
[Frode Hegland]: Hang on, e-Lightenment? Has anyone else on the call heard that expression before? That’s pretty cool. Let’s just underline that. The e-Lightenment. Okay, that’s wonderful.
[Jamie Joyce]: That was the name of my TED Talk†, yes, I called the e-Lightenment.
[Frode Hegland]: Oh, no. You caught us not having seen your TED Talk, now we have to watch it. Okay, fair enough.
[Jamie Joyce]: No, no. It’s old. It’s not amazing. I really want to redo it. If I redo it, I’m going to call it something like Big Data Democracy, and talk about the complexity, volume, and density of our social deliberations, and how we need new tools to really experience our big data society in the way in which it actually exists in reality. But anyway, yeah, so I think some things are relevant, some things are out of scope. There are a lot of people who are working on different dimensions of these issues. And one of the contributions that The Society Library is making outside of knowledge projects is also education. We’ve been working at the university level, we’re trying to bring it down to high school, and then we’ve been collaborating with some people ideating how we can start an epistemic appreciation, learning about cognitive biases, logical fallacies, and the various ways in which you can be disinformed on the internet into a younger and younger children’s programming to develop literacy, and a standard for what we should appreciate, in terms of, high-quality work versus not high-quality work. And obviously, there’s people who are working on making social media less effective and less addictive. There’s lots of different people who are working on this. And you’re right, I think a lot of politics is about personality. So what I think about often is, “Okay, well. How do we, essentially, make smart really sexy in the United States?”. So once we have these knowledge products, you have to create the demand for people to want to use them. So, what kind of people need to associate with these knowledge products?
[(IN CHAT) From Peter Wasilko]: Do you flag logical fallacies in the presented text?
[Jamie Joyce]:Yes, we do. So I didn’t mention it. Thank you for your question, Peter. We have a tagging feature and we use our tags and it actually appears on the paper. So when someone unpacks a node in the paper and we have a tag on it, it appears as a handwritten note off to the side in the marginalia that just lets people know like, Hey, this is an opinion. This needs to be checked. This is cherry pick data, etc. Sorry, I saw your note and just wanted to answer that really quickly. So how do we create the personalities? You know, fictional or not? These could be in kids’ shows, for example. How do we create the personality and personas that are sexy and attractive that are pointing people towards the cultural values of appreciating more rigorous research higher standard for argumentation and these sorts of things? And some of our donors and supporters have been thinking about this also. And thinking about supporting subsequent and related projects to help drive up demand for people appreciating this. And something that we see in the Trump era in the United States is that there’s been a huge decrease in trust. I think this was happening well before Trump, I think Trump was a consequence of this happening. But I think he also helped make it a little bit worse. There’s been mass amounts of distrust in existing knowledge institutions. Like news media, universities, government agencies, these sorts of things. Some sections of the population are not as trusting to get their information from those institutions. However, I think libraries, very interestingly, have maintained their level of trust in American society. So we do recognise that there is an element of branding and storytelling to be attractive to the community. It’s probably going to be very long-form relationship development. And that’s one of the reasons why the Society Library takes its culture so seriously. We take our virtues and values so seriously because we are going to be an institution that isn’t going to get thrown away immediately. That means we have to always have the out-facing communication, the branding, look, and the integrity to earn and maintain that trust.
[Frode Hegland]: On that issue, on the fake news. This [holds up book] (Snyder, 2018) is a phenomenal guide to fake news, as opposed to propaganda. It basically makes this simple obvious statement that, when Russia first invaded Ukraine, the point of fake news was not wrong news. It was simply wrong and true mixed, so no one would believe the media. And, of course, clever people like to think, “Oh I don’t trust the BBC”. And, you know, the situation we’re in today, which is pretty awful. And then I have a very specific semi-technical question, this goes back to having conversations with Marc-Antoine, of course, and that is, the last thing you showed, that normal document where you can click and things open, that is, of course, phenomenal, and it is something that, we in this community, we really like the idea of being able to get a summary and then digging into it. So my question to you is: In what way is it open and interconnected? Can I use it in my academic document? Can Fabien use it in a VR environment? And can Marc-Antoine, I guess you can, extract it into his knowledge graph? How does this data move around?
[Jamie Joyce]: Well, good question. So all the data coming from the debate map can be referenced and extricated elsewhere. The paper document is so brand spanking new, we haven’t even thought about integrating it with other platforms. So we’re still wrapping it up as we speak. When it’s finished though, I would love to start inquiring into, how it can be, not only maybe productised so other people could use it, essentially, it would require a different interface to input data. Most likely because I can’t imagine people are going to quickly get up to speed with our really complex debate map. So creating a user-facing product input form into a structure that will probably be more helpful to others. So I don’t have an answer to your question yet. I would love for it to be productised and for it to be ported elsewhere. But the debate map does, that data can be extracted and referenced and all of that through an API.
[Frode Hegland]: Marc-Antoine, do you have anything to add to that?
[Marc-Antoine Parent]: We certainly both believe in the value of making these new ways of expressing information, both in continuous text, in graphs, and making them interrelated. How interrelated, there’s many models. And I think we’re both, separately and together, exploring ways to do these interrelations. Certainly, the ability to tag concepts or arguments in text, I doubt very much that it won’t be connected to a graph realisation. In that way, if you have an export from the graph, the question is: Can you identify these things in the text document, right? And then we can speak about offline annotation. We can speak about edition. We can speak about… Somebody mentioned stretch text in the notes, yes, I believe in that. I believe in side-by-side views, personally. These are having the graph with the text coordinated, that’s something I’m pursuing. As I said, I’m not part of that team. I don’t know how Jamie’s doing that part. I am helping her more with the extraction a bit, so, yeah.
[Jamie Joyce]: Very much so. Well, you can join the team, Marc-Antoine. I’d love to get your thoughts. We’’ve just been so swamped in the world of design, I didn’t even think about tapping on your shoulder. But I always love working with you.
[Frode Hegland]: Yes, you two, yes. So, okay. I’ll do something controversial, then, and show you something. Just briefly. most of the people here know this all too well. This is the most poverty-stricken thing I could possibly show you. But it’s about an approach, not a specific thing. I’ll do really briefly. At the beginning of documents in a book, you normally have a bit of metadata. PDFs, of course, normally never have anything. So this approach that we call ‘Visual-Meta’, is to take metadata on the last page, right? This obviously wasn’t made for you, so I’ll just show you a few brief things and mention the relevance. It is formatted to look like BibTeX, and that just means it looks this is this, this is this, really, really simple, right? So this example here happens to be for the ACM Hypertext Conference last year† and this year. But the idea is that, all we do, when we export to PDF, is to write at the back of the document what the metadata is. And that includes, first of all, who wrote it, because very often, an academic article, when you download it, you don’t even know the date that was published, because it’s from a specific bit of the journal. It also includes structural metadata, i.e. headings. They can also include who wrote the headings and what levels. And then they can include references. So all of this is in the metadata that we then take into VR, or wherever, and use it. So one thing you might consider, and this is something we’d love to work with you, but if you do it entirely by yourself, that’s fine. All this stuff you have, when you do that top-level presentation, just stick it in the appendix. As long as you explain in the beginning what it is, in normal human language, let’s say, in 500 years when someone comes across the PDF and everything else is dead, they can reconstruct it.
[Jamie Joyce]: Yep. I checked out some of it, I think one of your explainer videos on it. I just got to say, I absolutely love it. I love it.
[Frode Hegland]: I’m glad you do. And thank you. I mean, every couple of months there’s a circle of arguments of, “Oh, we shouldn’t use PDF”. We don’t just use PDF. It depends where you’re doing stuff. When we go into VR, we use different formats. But at the end of the day, you’ve got to archive something. And that’s why it’s used by billions of documents. Somebody will keep it going. So when it comes to the finish bit, yeah, you know that whole workflow. I’m just glad we had that little back and forth. Any other questions? And by the way, Daveed and Karl, it looks like you’re wearing the same hat. It’s so funny. Because of the green background.
[Daveed Benjamin]: Oh, that’s funny. Yes. Nice. I have a question, Jamie. Where are you headed with the visualization on screens?
[Jamie Joyce]: We’re working on creating this multi-dimensional explorable and interactive piece of paper. And then, I think we’re going to move on to recreating the newspaper and recreating TV as well. Because again, all of those nodes can be the ones that have video content because we clip it where the expression of the claim is associated in video with the node itself. So, as especially we get more and more sophisticated with automating some of our processes, and making sure each one of the nodes are actually multimedia, I think the same way of compressing and compounding into a dense layered interactive set can be translated across medias. So I’m really excited about that. But again, I cannot state enough how interested we would be in creating a VR library, because I think that would be so exciting. Or a VR debate. I think that’s really important. So we’re just tinkering right now. And we’re just finishing up the last really complex argumentation structure and creating corresponding paper features and visualisations for that. And we’re looking to push it out by the end of this month. And then we’ll test and get feedback and see how useful it is and all of that.
[Daveed Benjamin]: That’s super cool. I look forward to seeing that.
[Frode Hegland]: Yeah, that’s really wonderful. I see Fabien has his hand up, which is great because I was about to call on him. I was just going to say two things in context for Fabien. Number one, we’re doing some basic murals in VR now. And even just a flat mural is really powerful. And we’re looking at all kinds of interactions. But also, we do meet every Monday and Friday. All of you should feel free to dip in and out as you have time, because right now we’re at the stage where we’re learning how to do folding, or this, and that. So we’re at the detail level which could be really quite exciting. Fabien, please.
[Fabien Benetou]: Thank you. And thanks for the presentation. What I wanted to say, I have a presentation due for this group named “What if a librarian could move the walls?”. I think it should pique your interest. But I’ll give a little spoiler for this presentation, which is to say, in my opinion, even if, for example, your information or your data structure is very well organised, it might not be the most interesting for participants, because that might become a little bit boring. If it’s too structured, let’s say, if you go to a hospital or a large public building, if every floor is a copy-paste of the other, we get lost, basically. So being structured is extremely powerful. And we can process and we can do quite a bit with it. But I don’t think it’s sufficient. It’s not a criticism in any form or way. I’m just saying, today if you give me the data set, I can definitely make an infinite corridor, a very long corridor, with all the information. But, yes. I think it would be fun to do, but I think it’s not sufficient. I think you will experience it, have a form of way to be through it, but one of the, at least my motivation for VR porting of text, documents, or information, is how smart our body is, and how we can remember when we’ve been to? Like I was mentioning a bakery in Berkeley, because I haven’t been for a while, but I did go and I remember how to get there, and how to go in the bathroom of a friend. This mind-blowing stuff that any of us, every one of us can do. But because we have some richness of the environmental diversity, So it’s a bit of a word of warning to say, porting it to VR it’s definitely feasible today. It’s not a problem. It would definitely be valuable and interesting. But it would probably be quite interesting or more valuable to consider what 3D assets you do have. Is there actually a structure behind, let’s say, an argument map? Can you actually visualise it, not to visualise it, but in a way that you mentioned knowledge is compression that you can synthesise in a way that is meaningful. Not just to specialise it in order to specialise it, but to specialise it because that mapping or that visualisation makes sense. So I think that’s a little bit of a challenge there. And again, I say this candidly or naively, I don’t have sadly an obvious or immediate answer to this. But in my opinion, that’s where the challenge would be.
[Jamie Joyce]: Yeah, I absolutely completely agree. And when you mentioned how intelligent our bodies are, what immediately came to mind is how, when we were looking at different visualisations for the data on, essentially, a 2D screen, where we can’t interact with it in a three-dimensional space, so to speak, I was trying to find a lot of inspiration from video games. So, I was looking at a lot of video games, of how they compress knowledge and organise it. They have all their accessories, and this is how they upgrade their armour, and blah, blah, blah. So I was looking at tons of those. And what I was really interested in and inspired by, were these things called star charts. So there are ways in which people can develop their character, where they move through a three-dimensional space of lighting up nodes and it essentially shows that they’re headed in a specific direction, it shows them enough of what’s ahead of them, so they know to move in a direction, Final Fantasy does this, for example. And they also know there’s a whole other section over here of undeveloped traits because their character is moving in a specific direction. And so when I was thinking about our argument maps, if we were to take those trees, and essentially lay that out in physical space, is there some kind of metaphorical thing that we can pull from real life that would map onto people’s brains really easily so that they could use their geospatial intelligence to, not only remember the content but be interacting with a little bit more? And I couldn’t help but think like, essentially roads. So all of these different signs that would indicate if you want to go to economic here, blah, blah, here, blah, blah, blah, here. And they could be taking a walk through the debate. And it could be an enjoyable experience because there could be lots of delightful things along the way that they could be seeing. As they’re walking in the direction of the economic arguments there’s another signpost with all the different signs pointing in different directions, they take this one, etc. There’s the map up on the corner showing them what territory they’ve explored. This is something that exists in video games. And I mean, given the structure of our data in debate map, it seems as though so long is similar to how we are designing all of the assets in the paper to unlock, unfold, split up, and blah, blah, blah. If those similar assets could be rendered in a 3D space, you could just map out entire territories of physical traversable space. So I don’t know, given that you’re an expert, if you think an idea like that could be worthwhile. But I completely agree with you that just visualising it as books or something on a shelf isn’t going to do it, because we’re a different kind of society now. And so, part of the reason why we conceptualise this idea of a web-based conceptual portmanteau is that we know that we have to develop new media to express knowledge. We can’t just directly digitise books, or pages, or essays, or newspapers anymore. It’s multi-dimensional.
[Frode Hegland]: But there is a really interesting ‘however’ which we experienced recently. Bob Horn gave us a mural that we put in VR. And if you pull it towards you and push it, no problem. But if you walk it’s so easy to get queasy. Motion sickness, for so many of us, can happen. So the idea of walking down a road it’s great for some, but it can easily just not go. But also, before I hand it over to Mark here, Brandel forced me to buy this book last time by holding it up, that’s how we force each other here. And the introduction is not very good. It really threw me off, because she’s a journalist. However, when you get to the chapters, the embodied thinking and so on is absolutely phenomenal. I think you would greatly appreciate it. But, yeah. The reason I highlighted that point is me having been in VR only three months now. Properly on and off. I had so many preconceptions that are just getting slaughtered. So to work with Fabien, with such rich deep experience, and also with Brandel, who’s working on these things to really learn to see differently, we have to re-evaluate this. For a while, we call what we’re working on, Metaverse. But just looking at the proper definition, that’s all about the social space. What we’re doing in this group is not so much social and definitely not gaming as such. It is about working in virtual environments. And it seems hardly anybody’s focused on that. So for you to come into this dialogue with actual data, actual use case, actual needs, that’s a really wonderful question. So, I want to thank you very much.
Jamie Joyce: Yeah, and thank you for that advice. And thank you, Fabien, too. So, are there meetings that maybe I could sit on so I could benefit from this sage insight and experience of translating things to VR?
[Fabien Benetou]: Sorry to interrupt, but to be really direct, did you put up your headset for the last couple of years?
[Jamie Joyce]: It’s probably been about a year since I’ve put one on my face.
[Fabien Benetou]: Okay, but you did. So that’s fine. Because, I think, honestly, with all the due respect to everybody around here. Putting their heads at once recently is more valuable than any or all of our meetings. And then coming in, discussing, and then, proposing a data set is definitely valuable. Yeah, but that’s the first step. You’ve done that part, you’ll get it.
[Jamie Joyce]: Yeah, I’ve played some games. I love the painting games a lot, actually. That’s pretty fun.
[Frode Hegland]: Very good. Just to answer your question about sit in. You’re all invited to just be in any of the meetings. It is the same time. It should be four to six UK time, but you Americans move the whole clock. So we follow you. Right now we will catch up with you. But sit in, say nothing, speak, whatever you feel like. It’s just a warm community. Mr, sorry, professor, not professor, Dr. Anderson.
[Mark Anderson]: Okay. Well, thanks. I really enjoyed the presentation. And I’d love to hear someone just mentioning the idea of a data set because given the deconstruction you’re doing, there’s something really interesting there. At the moment, when people talk about data set, that just means “something I scraped out of an excel spreadsheet and shoved in a box and I now think it’s worth money”. Fundamentally not what I think data is. And it’s really interesting too for this thought of VR, one of the things, so I’m kind of completely new, I suppose, two months, I guess, since I’ve looked at any certainly any mode in VR, and I’ve been using Oculus. And then, one of the things I’m really seeing is that lots of things that you’d think would work, just won’t. So take pretty much any 2D print visualisation you’ve thought of, it’s not going to be instantly better for seeing it with an extra D. That’s for certain. Which is, in effect, why the data is so much more interesting. So rather than think, “How do I make this picture, this 2D picture appear in 3D?”. With all this richness, “how can I see things that I can’t show?”. Anyway, probably something that preaches to the converted there. Just a couple of thoughts but against you rather cheeky and I feel bad about it because they’re only possible to make given the mass amount of work you’ve done and the wonderful deconstruction of the arguments. But I suppose the hypertext researcher are used to looking at non-linear paths and I was thinking, does your deconstruction process show you where the same sources or the same arguments occur in multiple parts in the graph? Because I think that becomes useful. And also, the whole ‘Johari window’† problem of the ‘unknown unknowns’. There is a danger and we’re all prone to it, is that, because it takes time to do this, by the time you’ve mapped everything out, that seems like the known world. And I can’t see how to still force myself to say, “Ah, that’s just the bit I know. Now let’s look at the broader thing” I don’t know if there’s an answer to that, but it’s an interesting challenge. And the one other thing I was thinking about prompted by the thought of changing views about how we trust data, sources, and things is, we seem to have moved into a world where there are massive first-mover advantages in being the first to complain, for instance. So there’s moral ascendancy being the first person to call the other person bad, regardless of the truth or situation. And it also tends I’ve been a thing creeping away if there are two pros and one con or vice versa, that’s seen as actually being an empirical measure of work. How do you cope without or does the deconstruction model not attempt that? Because I’m not saying it should, but what are your feelings on that side of things?
[Jamie Joyce]: Yes, okay. So there are a couple of different things that you said and I’m going to try to remember and respond to them all. So, One—can the system understand that the sources are the same? Yes. But there’s no features built on top of that to make that easy. And it’s deceptively linear because we can actually copy and paste nodes all across and it does link all around it. And if we update one, it updates the other, etc. So it’s deceptively linear. But definitely, it could be more rich and useful as a knowledge graph if we build features to actually filter content like that. We don’t currently do that. The other thing that you mentioned is about knowns and unknowns. Actually, we’ve had extensive conversations at the Society Library about this very thing, because we have this technique called ‘Devil’s Advocacy’ research. It’s something we borrowed from the CIA. So, if you take a claim and you just invert it to its opposite, and then, you go and try and steel man that, that’s a CIA technique at least as recent as 2009. And so, because we generate so many claims, I think our climate change database is like 396 thousand claims of a single expression, not variant phrases but single expressions. We could just invert all of those and have a whole other set. And then there’s, of course, you don’t just invert things in a binary sense, there’s all these shades of grey in between, there’s all these adjectives that you could add that slightly change the meaning of a claim. So there’s a lot that we could do there to, essentially, once we have the set that we have, the known, knowns, to invert, slightly adjust to drastically expand that. And then what we could show as visualisation and we thought about this, would it be a useful epistemic tool to show people? This is what we were able to steel man, but these are all the different research questions we have, that we were just able to generate that are relevant to a certain extent. It’s not just nonsense created by GPT-3, right? It could be relevant and we haven’t done the work yet. And we didn’t know if that would be that would increase intellectual humility and curiosity, or that would be really disincentivizing and discouraging. So it’s beyond our organisational capacity to that experiment. But we have been thinking about and are interested. When it comes to trust first movers, I see people coming into this space and being the first movers of complainers and I’m seeing them rise in popularity and it’s very interesting to watch. But I can’t remember why you brought that up.
[Mark Anderson]: Well, it bleeds into this point about people getting overly empirical. So, “I’ve seen two supporting things. So clearly that’s more than one countervailing argument”. So, in other words, not just the user, the learner from this not actually learning, they actually have to evaluate. Having got to these sources and actually having to evaluate them. It’s not so much just counting up pros and cons.
[Jamie Joyce]: Yes. I’m going to quickly see if I can pull this up really fast. So we’ve been thinking about that also. And one of the reasons why we have tags is to start qualifying things so we’ll call out if an argument has no evidence since it’s just an opinion or logical fallacy, etc. Because we’re trying to combat some of those cognitive biases. And so one of the things that we want to do as clunky of an idea as this is, we do have an intro video where we’re going to try and prime people to not fall for these different cognitive biases. To tell them explicitly do not fall for this trick. Having more does not mean this is better argumentation or what have you, do not fall for this trick. We’re thinking about making it so that you can’t even unlock the paper map decision or library until you play a video that helps inoculate against that. And something that I’ve been just personally wondering is, can cognitive biases cancel each other out? So if people are one: more likely to remember the first thing they read, but they’re also more likely to remember things that are negative, should we always show the con positions or the no positions at the end? And should we, in these intro videos, tell them that there’s no way that we can get around some of these biases? Because they’re hardwired in our brains. We’re just primed for them. So we’ve organised things in this way. If you think it’s biased, it’s because it is, but we’re trying to counteract this other bias. So we’re trying to find that, is there a communication medium whether asking them to watch a video or have a little character pop up, a little tiny robot librarian bloop up and be like, “Hey, just so you know, we did this for this reason because humans are biased and flawed and we’re just really trying to get you to enlightenment here”. We’re thinking about it. We have no great answer. And we do have a partner at Harvard and NYU who offered to run a polarisation study to see if the way that we map content can depolarise attitude. So we are interested in partnering with universities to really rigorously test some of the features that we’re thinking about, just to see if it does have a pro-social positive impact because we’re not interested in persuading anyone. We’re not interested in driving anyone towards any conclusions. We just have the librarian goal of enabling enlightenment through access to information. And for us, enlightenment means potentially open mind through depolarised attitudes, inoculation against disinformation, intellectual humility, increased subject matter knowledge and increased comprehension of complexity. So just overall more curiosity, open-mindedness, and comprehension without being inflicted by bad attitudes, depolarisation, disinformation, and things like that.
[Mark Anderson]: Well. that’s lovely to hear, actually. And I’m thinking, of course, that again, the joy of you having such a deep and rich data set is, for instance, although, you can’t necessarily answer some of the stuff on these biases, there’s a lovely substrate for someone to work on. I mean this is again where I think people fail to see where the real value in the data is. It’s not like you’re going to sell this to somebody. It’s the fact that it’s just hours of dedicated work. And especially doing it from, in a sense a neutral, for a want of a better word, but a standpoint which tremendously important because you rightly stay. I mean if you’ve got some bias in there or if you’ve got more than a trivial amount of bias in there to start with, then you’re building on sand. And just because I see hands up, but one final thought is, when you mention the fact, yes, inputs to turn up across the piece. That, for instance, might be an area where having extra dimensions visualisation might be exploitable because it’s really hard to do on a flat surface because the worst thing is all you said end up with lines all over the place, and it’s alternatively complicated. But I think that one of the things that are submerging in our exploration of what VR is its ability to, you don’t necessarily have to remove things, it’s reducing the salience of some things. Bringing it, dialling it upon others. So it’s all there. It’s all somewhere in the space, perhaps. But what you’re seeing is the connection that’s pertinent at the time. It’s a different sort of interaction. You will ask for the thing you’re interested in knowing and bring it forward. Of course, thinking that and making that up is the journey we’re on at the moment. But, thanks. I find that really interesting.
[Jamie Joyce]: Thanks for your questions, Mark.
[Daveed Benjamin]: Excellent. Hey, Jamie. So my question is, well, the premise of it, is that what you’re producing is going to be incredibly valuable, I’m just making that assumption. And I’m also looking at it and just seeing it, seems like there’s just such a tremendous amount of work that goes into just one inquiry. And what I’m wondering is: What does it take right now, for example, to do something like the California Nuclear Plant both in kind of human resources, as well as elapsed time? And then I’m also wondering what do you foresee in the future, in terms of being able to streamline that with both automation and potentially AI? What do you what are you shooting for, in terms of human resources and elapsed time? And then, the third part of that is: Is decentralisation, at all, on your radar in that possibility of bringing in a much larger group of analysts to do certain pieces of the work?
[Jamie Joyce]: Yep. Great set of questions. So I believe the Diablo Canyon Power Plant project is about 10 weeks old. We got two more weeks left to wrap it all up. And that was inventing the paper visualisation along the way. We had four full-time analysts. I was a part-time analyst. So it’s kind of a small team in a relatively quick period of time and I think we owe a lot of that to the tools we built ahead of time in the past and our methodology. And the fact that we have years of experience training students through our educational curriculum, so we know how to train people to like quickly understand debate map, quickly understand what we might claim, use the tools to find content, but I honestly think, a lot of the different tasks, not the work, I think we’re going to be working with librarians and human analysts for a long time, but I think a lot of the tasks, discrete tasks, can be automated. We’re tinkering with some of those right now. I’m fundraising for some of that right now. I’ve got a lot of ideas about what’s possible in both like claim mining, syllogism generation, mass deconstruction, there’s a whole bunch of ideas that I have. And there’s already tools that exist that we could be experimenting with more. So I’m excited about that. You mentioned decentralisation, I think there’s a question between that. With decentralisation, the thing is that, language is so flexible and dense, and some people are not very precise in their expression. So it depends upon the knowledge that you are working with, first of all, because we’re working across different media types, there’s a lot of flexibility in that language, there’s a lot of ways in which people can misinterpret, they can imply, they can bias the interpretation. So if we were to welcome more of a crowd, there would be discreet tasks that I would allocate to them. But I would not trust a crowd to be responsible for the emerging structuring of a deliberation. And that’s because, unless this entire crowd is somehow really well trained in understanding what is relevant argumentation and what is not relevant argumentation, you’re going to end up with a humongous spaghettified mess. If you look at existing platforms, I’ve looked at a lot of platforms, if you look at existing platforms, you’ll notice that the argumentation is either very vague enough, where a lot of the relevance can be applied. Or it’s not really fine enough in terms of actually establishing the logical relationship between the points even if the points are more specific. So it’s not to the level of rigour that we’re interested in the Society Library. And that’s because like the knowledge project products that we’re looking to create, even though we’re creating the options for people to simplify things. Simplify this and put it into simple variant phrasing, for example. Just give me the gist of it. We want to give people that option. We actually want to do, as rigorous work as we possibly can, in terms of deconstructing arguments into their processes and conclusions. Because if I feel like if you don’t do that then it’s always going to yield more and more argumentation because people will misunderstand what’s implied. So, if you actually pull apart the argument like, “This is every single stage of what we mean. This is all the data that supports those things”, maybe it allows some tiny small subsection of readers to really appreciate that more. A lot of people are not going to want that level of detail. Just give me the gist so I can see and make my decision. So there are certain things I think the crowd could do really well. I think archiving is something the crowd could do really well. I think tagging is something the crowd could do really well. Modelling argumentation I think that’s a really high skilled skill. I think that’s a really technical skill and I wouldn’t trust like a hundred thousand people to do that in a meaningful way. I already get in wiki wars on Wikipedia, for example, and that’s just an encyclopaedia page and there are no rigorous rules about the relationship between sentences and Wikipedia. And yet, people still fight about that. So yeah, that’s my point on that.
[(IN CHAT) From Marc-Antoine Parent]: That does not mean that it cannot be partly crowdsourced in principle, but certainly not naively
[Jamie Joyce]: Yeah, partly crowdsourced in principle. That’s right. I agree. There are parts of it that could be crowdsourced like finding the topics, getting the resources, finding how topics, and base arguments appear in certain resources. So again, archiving and tagging, I think it was a great crowd job. But modelling, I think requires a lot of skill and a lot of editorial review. I review the work of all of the analysts. We review each other’s work. In the future I want us to have more of an inner coded system, where a lot of the work is actually redundantly performed, the same people performing the exact same task so we can actually see the difference, and see if that difference is statistically significant. There are people who build distributed content analysis platforms that I really like. They’re friends of ours, they collaborate with us on certain things. I’m not yet finished with fine-tuning our method enough to know what we want to have as a part of distributed content analysis and what can be automated. So maybe a few moderations down we’ll have the right combination of like, “Okay, we’re going to hard code this modelling into something that is distributed”, and then also have AI help us with certain discrete tasks, and maybe a crowd. We’ve been poked and provoked to do a DAO, as well. So, I don’t know if we will, but.
[Daveed Benjamin]: The question that that was in between was actually related to the first question. In the best of all worlds, where do you see the elapsed time getting to… Because, especially, when we’re talking about a culture with this first complaint dynamic happening. It’s like getting this information out quickly, I think could be really valuable.
[Jamie Joyce]: Yeah I like to think and try to orient our work towards constantly imagining it being possible instantaneously. There being constant monitoring, construction, and modelling that’s happening, I think we’re really far away from that. But that’s what I would like to get to. Essentially, the Society Library, being a large enough institute to have the manpower to respond where we need human analysts intervening, and also the technology to be observing, deconstructing, labelling, and doing base categorisations. De-duplicating these sorts of things. Finding the right combination, a lot of the unloaded work is being done by AI, and we have enough staff, librarians, essentially, serving society quickly, modelling up this content, where just absolute elite experts, and then, having all the tools that they need, in order to quickly do that. So, journalists are reporting and stuff is happening on TV we can be quick on incorporating that into higher dimensions and more complex mapping, epidemic mapping of a situation. So I’m hoping one day, I don’t know if it’ll be in my lifetime, I’m probably underestimating technology, but I don’t always imagine that it’s in my lifetime, but I’m angling towards us having an instantaneous institution for this. At least for publicly accessible knowledge.
[Frode Hegland]: I see Fabien has his hand up, but I just want to say thank you for something very specific. And that is surfing the line between being popularist and being arrogant, or elitist. Because I do think it is really important to still value expertise, and our current culture isn’t so happy with that. I’m sure you have seen ‘Hamilton’. I’m sure you remember Aaron Burr, I could have a beer with him, right? This is horrendous damage that is being dealt to us. So by you standing up for expertise without being arrogant, without taking a position, that’s just fantastic. So, thank you for that. And, Fabien?
[Fabien Benetou]: Yeah, my question is, and maybe I missed it, but how do you interact with the result? Or how does somebody who wants to learn, let’s say, get the expertise out of a topic, gets that? What I saw through the presentation, and again, maybe I misunderstood, but was unfolding the different part of the map. But is there another way to interact? I’m asking this specifically to see also again how could this eventually be coded or considered for VR? Because a visualisation, of course, is an object and you can see it but you can do more with it. You can, for example, fold and unfold, but once you got, again for VR, their controllers, or even your hands, you can manipulate it. Or if it’s text, you can copy-paste it. So they are very different and rich interactions. So, yeah. I’m wondering what’s the styles of interactions right now? And what was the thinking process behind it? Because more interaction doesn’t necessarily mean better. You want to concentrate on something productive. So, yeah. If you could dig a bit more there, I’d appreciate it.
[Jamie Joyce]: Yep there’s a couple of different visualisations that we currently offer. It’s essentially the same data, but we compress it and organise it differently. For some visualisations, we filter things out. One thing that we do is we do make the map available. People can un-click and expand and do all that. I don’t think a lot of people are going to find that attractive. Some people are going to love it. Two is, we’re revealing something called Society Library Papers, where all of the data in that debate map is actually structured in a piece of paper, where you can click on the lines and it opens up options to further unfold, not only the argumentation but into the note itself. You can refresh so the different phrases and different ways of expressing things show up. You can press keys that will swiftly change it from technical to simple language. So you’ll have your standard way it’s expressed, you can flip between those like, “Show me the more technical. Show me the more simple”. It unpacks the argumentation. So, Papers is the new thing that we’re rolling out. The other thing that we do is create decision-making models. So we just zero in on one sub-section of argumentation at a time, and people can add values to how they’re weighing the different arguments. And then, essentially, we ask them to micro vote. Where is the strongest argumentation in this one subset? And then they move on to the next set, and they move on to the next set. At the end, it’s shown to them like, “Okay, well. Where do you stand on these issues? Economic, environmental, etc.”. The decision-making model is the thing that we do at City Council. And then the other thing we do is we just make all the resources that we generated available in a tech searchable library. So you can look through all the references that have been included in this data set, you can keyword search and find the claims not necessarily associated with each other. You can search it on the map as well, so it’ll bring you to the part of the map where that claim is. And that claim can be in multiple places, so you can bounce around and see where all the places that this claim is. Or you can just search it in a library list. So those are the four things that we have, in terms of visualising content now, but I’m excited about, thinking about doing the same, kind of, paper unpacking and unfolding, but with video. And then unless we do something specific, like write legislation. We also have a designer who’s working on a phone app version of it. In terms of being able to interact, for example, with the paper, you can click on any line and it gives you the option to expand it in various dimensions. Show it to me in a video. Show it to me in a podcast where the references that, support this, where the bearing phrase is, etc. It would be so cool if in VR, and again, I don’t know if this would actually translate well. It’d be cool if you could take a statement and actually open it up. Grab that statement, open it up, “Oh, I can see all the videos, TV clips, where this occurred”. Swipe to the left, okay, here are the references. Okay, definitions. Okay, media artefacts. Okay, close that one up, star that, want to look at that later, grab the next one, let’s open that up and take a look at what that looks like, or do a motion like this, and it just spills out all the different claims that support it. I think there could be a lot of cool interactive ways that could make text a little less boring, simply because you’re moving your body. And moving your body may create endorphins, and make you a little bit more happy and excited about stuff. And that’s what we’re trying to do with Papers. With Papers, I didn’t show you any interactivity at all, I just showed you the mock-up. But we’re really focused on how it feels. The slickness of the unpacking. The slight little sounds. We’ve been looking at the colours when rendered to accommodate for different like visual, I don’t want to say impairments, but different visual differences. And it looks gorgeous, all of them, in my opinion. So we’ve been really focusing on the feel of it. Because we know it’s limited by text, but if we could translate that to VR, I think, it could be much more interesting just by being able to literally work with knowledge. Grab knowledge, put that over there, unpack, all that stuff.
[Fabien Benetou]: A quick remark on this, I don’t know if you’re familiar with the interactive explorations. Basically it’s the idea that you can have exercises in the middle of a piece. You don’t just have a piece of text but, you have an exercise. And it’s not just a textbook exercise, but it’s part of a story. So that you, in order to get the core idea of this article or concept or paper, you go through an exercise. So it’s a guided interaction, basically. You’re not just freely moving things around, but you’re solving a small challenge that’s going to get you to this eureka moment that the author of the paper had at some point and that’s why they were sharing this some kind of information. And I think that, also, is something that could be valuable. Of course, freely manipulating, but a guided manipulation that makes the person, who has to interact with, get the point of it. It could also be quite interesting, I think. Here, I don’t know how literal or metaphorical you want to be. Let’s say, you display a nuclear power plant. How close you are. You can zoom in and out to the atomic level or not. Yeah, there is a lot that can be done there.
[Jamie Joyce]: Oh, sorry. I didn’t mean to interrupt you if you saw my hand waving, because I got really excited. That’s good because we did a mock-up once. We didn’t get enough money for this project. But we actually did that for our Covid collection. So we built a 3D lab. We just did this in Prezi so it was a very superficial mock-up. We did it in Prezi because it has that zooming in and out feature. And we built a 3D lab where you could essentially zoom into the lungs of the lab worker who was there and explore all the different argumentation about respiratory health, and what Covid does to the body. You could zoom into the microscope to learn about argumentation about what SARS-COV2 as a virus is, what are its features, what are the pictures that have been grabbed, what kind of telescope, etc. We did that, where we built a scene and people could zoom into different dimensions of it, to explore different topics, sub-topics of debate within that. But we didn’t get enough funding to really do for real. But I think that would be really fun.
[Fabien Benetou]: The funding part, to be honest, it’s about to lack in the sense that, it’s super demanding to get this kind of materials. Designing a 3D experience. But I think for those two cases, nuclear or Covid, they are excellent for it, because there are skills that are not graspable for most of us. And I think for a technical expert then it becomes natural because you did the exercise so many times that it does become natural. But being able to change scales, in a way that still makes the intangible, tangible, it’s a perfect use case for this.
[Jamie Joyce]: Amazing. I’m excited to sit on all these meetings.
[Frode Hegland]: Peter are you is that an earlier hand or is that a fresh hand?
[Peter Wasilko]: It’s an ongoing hand that’s been having things added to the queue. Your description of waving your hands around reminds me a little bit of the user interface depicted minority report. That was a very interesting movie to take a look at for the VR-type visualisation. Well, more AR-style visualisations in it. Also the talk about instant votes and things remind me of a wonderful episode of The Orville called ‘Majority Rule’ where everyone would walk around with smart badges that had an up arrow and a down arrow. And if you accumulated too many down arrow votes, you’ll be lobotomised by the society. So, just fascinating. Then substantively, have you taken a look at the foresight literature? There’s a concept called ‘Futures Cone’, and I put a link for that in the chat. The basic idea is to represent multiple possible futures. And it seems like that could be a good visualisation for providing an organisational access layer to the dialogue, because some of the different points would correspond to the same possible future. And that could provide a different view on the evolving debate structure. So, for instance, there would be one possible future where the claims that the climate temperature is going to go out of control is correct. Then there’s another possible future where it turns out that those studies might not necessarily have been accurate, more an artefact of modelling software. So you could take those possible futures and represent them in a visualisation, and use that as a filter onto the debate structure. Also, another very interesting diagramming technique is the use of state machines. Very popular in computer science. And it’s been touched on in linguistics and parsing to some extent. And the notion there is that you have a series of states, with transitions between states, and you could associate different arguments with transitions between states, where the states could represent possible futures in the futures cone visualisation. Also, I would suggest having a look at the system dynamics literature, which has its own suite of visualisations. Some of which are very nice web-based tools that look at feedback loops between different stocks and flows. And that again could provide a filter into the diagram structure as some of the diagrams would relate to different elements in that visualisation. So those are a couple of possible filtering access layers that you might want to have a look at. I have all the links to the side chat.
[Jamie Joyce]: Thank you so much. I think I found everything that you post in the side chat. I super appreciate that. Getting some interaction interfacing with the forecasting community has been of interest. But I haven’t had the capacity to explore what is the extent to which they model futures. Because I obviously would be interested in taking those projections, deconstructing it and seeing what it looks like, in terms of, translating it to Society Library language and concepts, so I can get a handle on it. But I haven’t had the capacity to check that out. But thank you for these links, because it’s definitely on my list.
[Frode Hegland]: Talking of links. First of all, as you know, this will be transcribed and put into the journal, both your presentation, this dialogue, and the chat log. So whoever’s interested, go and have a look at our first two issues. Mark and I are still learning how to make it navigable because there’s a lot in there. But then my question is actually quite different and that is, a few years ago I took an online quiz in a Norwegian newspaper on politics, and it asked me, what do you think of this, what do you think of that? Click through, very simple. At the end of it, turned out that I should be voting for the Christian Democrats. Which was a huge surprise because, whatever. But so my question to you then is: Have you considered letting your users model themselves in such a way, so that when they go into this, they have a stated position that the system understands that is based on their answers?
[Jamie Joyce]: I mean, when I think about those kinds of quizzes, the first thing that pops into my mind is, I really want to see the data that they’re using to suggest that. Because I want to know if their interpretation of this candidate’s position is the same as the language I would use to describe my position, interpreted by the language that they’re giving me, maybe a multi-choice format to express it. So I personally have trust issues with those particular things. There are so many different possibilities to create products from these data sets.
[Frode Hegland]: I’m thinking not necessarily about the quiz, because, yes, that may just have been a journalistic gimmick. I’m thinking more about coming in and let’s say, most of us here, we go and say environment concern, high. We state where we are on specific issues. Health care should be shared or not? Just a few yes or no. Because that’ll put you because you talked about a constellation earlier, there’s also the thing, the spider graph, where you have lots of different dimensions and you can then see the shape of different people. But as long as people can be shown that dimension of themselves and say, “this is who I believe I am”, that may help their interaction, somehow. I don’t know if I’m going on a huge tangent or not.
[Jamie Joyce]: I mean, one thing I think is interesting is that, these types of quizzes, whether it’s Enneagram, or Myers-Briggs†, or whatever, people love to conceptualise themselves, I think. These things are popular because, within a certain subset of people, they want to call themselves and identify themselves as something. Just being like, “Oh, I’m INTJ. Or I’m ‘this’ or ‘that’.”. Some people really love that stuff. I think that could be a cool offering in terms of, “Here is your graph of beliefs”. Like an astrological chart. Here’s your sun sign and whatever sign. Here’s the dimensionality of your beliefs. I think that could be cool. But also, you made me remember something, which is, when we were talking earlier about trying to combat cognitive biases, and I mentioned that I believe it’s the cognitive bias that people remember the first thing that they see. Or people may have a backfire effect if they see something that immediately contradicts what they already believe. So people taking a quiz upon being introduced to a new subject, it would require for us to have an account system. They’d have to create an account, so we can remember these preferences. I think it could be, potentially, a way to combat bias if we knew what people strongly held beliefs are so that those could be expressed first, and then, they can be confirmed as being understood. Because I think that’s how you can overcome backfire, is you let people know you model to them who they are, we hear you, we understand you, and here’s the strongest version of the thing that you believe, here’s everything that you could possibly want, and now let’s go explore everything else. So I think that would be useful. Again, to start changing the way we interact with information, to enable enlightenment and open-mindedness for people who want to opt into something like that.
[Frode Hegland]: Yeah, I think that’s very interesting what you’re saying because a cognitive bias is not a bad thing, in and of itself. Same as prejudice. Also, is not a bad thing, in and of itself. Without them, we can’t function in the world. And, of course, who you express you are, depends on the circumstances where you are asked to show who you are. I do think it is really an important issue because, for instance, our son, beautiful four and a half-year-old, Edgar, he goes to a Catholic school. But we weren’t sure about putting him in a religious system. But the reason we decided to do that was, I’d much rather argue morals with him at home, rather than him go to a school that doesn’t allow that. And then, try to teach him to be nice, because a lot of these decisions come down to how do you see your neighbours, how do you see yourself, how do you see the planet, all that stuff. Everything is filtered. You can’t argue facts is something we keep being told again, and again. So I’m just wondering, you have this incredible information landscape that is intelligently put together, if there was a mechanism of someone, maybe even stating their beliefs, and then when they go into the system finding out that they’re not actually behaving within their stated beliefs. The typical thing being a right-wing Christian. There’s no chance in hell Jesus was a right-wing Christian. As an example. To not only get the information in, but having a thing that is representing where it goes in.
[Jamie Joyce]: I think in the future we’re going to have a lot more capabilities to do things like that. And I hope so because knowledge and information is so powerful and impactful, and if we could just improve that relationship or objectify knowledge and have a new type of etiquette around how we interact with it, and allowing it to change us, and open up us. And mirroring that it understands us and can, again, contrast us. I think that could be really wonderful. I think it’s far out for the level of sophistication that you’re talking about, or I’m just failing to imagine. But I hope we get there, because I think that would just be so lovely. I personally love to think of humanity as a species on an information diet. I think how we really survive is on information. All the different inputs that we have. I think making that relationship even more sophisticated is, hopefully, in our future and for the best.
[Frode Hegland]: Yeah, that’s wonderful. And sorry, as a just a tiny little thing, and that’s, if you read Jaron Lanier’s book† on his VR experience journey, it’s very little about the environment and very much about the self. How you change yourself in the environment. So to think about this, in this context of being able to go into this information with an awareness of different ways you are yourself in this space. I know we’re talking a huge down-the-line kind of thing, but it was just interesting to hear that. Right, Mark. I will shut up for a minute.
[Mark Anderson]: Okay. Very quickly because I see other hands are up. And just to restrict myself to just one observation. Another thing I think is interesting that comes out of the really interesting deep landscape, data landscape you’re making, is the ability to look at the, well, almost the meta-metadata. So when you look across the problem space, where are the references coming from? So, in other words, there’s a whole skein that goes over the top of this, which is not part of the augmentation or argument discovery, per se. That’s quite useful in an intelligent, very small ‘i’ sense, in terms of, understanding the problem environment space, I think. Anyway, I’ll leave it there because I see there are some people, and some haven’t spoken yet.
[Jamie Joyce]: I will just say quickly, Mark, what you may love to hear is that we do take great care to steel man things. So if we find arguments on TV or in news, we will try to see where is the rigorous academic literature on this. So it’s not just by luck that we’re identifying and associating arguments with media types, because we always try to get the most rigorous as possible, and the most accessible. So if it exists in different media sets, we’re really looking for them.
[Mark Anderson]: Yeah, it’s just this interesting thing that sometimes now, it seem certain sorts of arguments seem to come from a… Or in a certain type, I don’t want to typify it too much because then you get into the labelling, but it’s just the sentence that, whereas you might think it’d be distributed across the piece, going through all channels, or all age groups, or whatever: it can be quite fragmented. And that’s the kind of thing that the rich data that you’re collecting also enables you to see, I think.
[Jamie Joyce]: Yep, I agree. Okay, who would like to go next? Karl or Peter?
[Karl Hebenstreit Jr]: Yeah. I posted a link on, Peter Elbow had this article about the ‘Believing Game’ and it’s some nice connection between that and the ‘Six Thinking Hats’. So it’s systematically speaking validity in what you don’t agree with. And then, it’s interesting with dialogue mapping and Jeff Conklin’s. Both Jeff and Edward de Bono, they focused so much on dialogue mapping and Six Thinking Hats being a meeting facilitation process. But then, there’s also the whole individual sense-making process too. I’m very big into dialogue and the facilitation process. How do we get people engaging in real-time? A thought I had to bring that to your attention.
[Jamie Joyce]: Yeah, thank you. I copied those I’ve never heard of the Believing Game or the Six Thinking Hats, actually. And I think that there’s a lot that we could learn from bridging communities and facilitation communities. Because what we’re trying to do is a technologically induce a space where people can interact with knowledge maybe as if and the different positions maybe as if they were interacting with a person. We’re not simulating that. But like what are some things, in terms of, the visualisation itself that could create that container? That would make people feel receptive and that sort of thing? So I think there’s a lot that we can learn, and I try to pick up things here and there from facilitation, mediation, and bridging, to learn those things.
[Marc-Antoine Parent]: Just a quick thing. I mean, Conklin—I’m working with Jeff Conklin right now. His work really shows the value of facilitators in de-personalising arguments and creating these syntheses, usually in real-time. And I think it goes with what we were saying earlier about the importance of argumentation as a skill. And this was synthesis map-making and consensus making as a skill. And, yes. I agree totally. The question is how to weave individual sense-making, which is a more and more important activity, into creating these synthesis maps? And the question of creating synthesis from individual curated maps to collective curated maps is really the key articulation. But it’s not going to be just crowdsourcing, it has to be learned. And there are many paths towards learning to do that. And it has to be social learning about how to create these consensus maps.
[Karl Hebenstreit Jr]: Just one quick thing too with the way Jeff separated out. So you have the issue mapping, which is gaining the competency with compendium and creating the maps. And then there’s the dialogue mapping, which is the facilitation process. I think that’s really important for all these tools.
[Marc-Antoine Parent]: I personally believe, sorry, Jamie, we will need more than one mapping when we will need to connect them. For example, I think what Jamie is doing is a wonderful epistemic map. Why do people believe this? And someone was bringing these future maps. But when you do a future map it’s, this may lead to that, this may lead to that. It’s a totally different temporal presentation. They shouldn’t be on the same map. But you would want to know why do you believe that this may lead to that, which is the epistemic dimension. Connected to that and vice versa, right? Why is the belief that this may lead to that also feeding into the epistemic questions? They’re different representations. I don’t think there’s ever going to be one representation to them all, but we need to make a representation (indistinct).
[Jamie Joyce]: Speaking of communication. One of the things that I was thinking too is that I’m not a facilitator. So I have very limited knowledge of what that tails. But my understanding is, facilitation and mediation include deploying all sorts of different communication techniques to position people in the space where they can then proceed with a conversation and interact with something that’s potentially conflictual. So I’ve been thinking too is, maybe there could be, in thinking of how do we borrow from facilitation to enable interaction with our content in a successful way, it may there be a chat bot feature where we turn it on different facilitation communication strategies. So someone’s interacting with knowledge. And someone’s going off track, they know how to like, “Oh, hey. Okay. Let me reframe what you just said, and let’s move it now over back to the map”. So there’d be a relationship between a chat bot that could carry on the conversational AI element, to walk people through the epistemic map, because it may be too dry to ask someone to go back and forth, pro and con, down from a position to more precise argumentation. That may be too much. Besides readers who are just generally interested in exploring a deliberation. But in deploying it to a chat bot, integrating it with that, I think is something that could be in the future, as well. And if someone isn’t already working on capturing all of the facilitation techniques, I hope they do and they train an AI to be having that, would be cool.
[Frode Hegland]: Yeah. You’re talking about something being too cold. I think that’s a very good question here. You’re building an incredible intellectual tool and of course, emotions will come into it at some point. So you’re enthusiastic for VR and I think you understand VR like we do. Just multi-dimensional. Doesn’t matter if it’s a headset, or whatever particular. Will definitely come in to make people feel more embodied, more involved, and more aware. One of the great things about this book† I keep holding up is, it points out that, if you want to be more rational, you listen to your body more than your head. Your head is more emotional than your body. Which was a bit of a surprise. So, we can help people get those understandings. I’m not sure why Brandel is not here. He’s always available. He’s very involved, so there must be a good reason. So when he watches the video of it at some point, we miss you, Brandel. I hope to see you together with the group soon. We have seven more minutes. And Peter will have one of the final questions.
[Peter Wasilko]: All right. I was wondering whether you’re doing anything to flag bias of the sources that are behind the sources that are being referenced in the articles? A very common phenomena is that you’ll have some group with the name like, ‘Concerned parents trying to improve safety in schools’ and etc. Then you look at it, and you find out that it’s really a front group for gun manufacturers. Or you’ll have a piece of legislation and the name of the legislation is the exact inverse of what the functional result of the legislation would be. Also, I was wondering whether you’re looking at pop culture as sources of argumentation too. There’s a wonderful wiki called TV Tropes that has links to just about every single movie, book, manga piece of resource out there. Plus they also cross-link examples of those probes in real life. So, you can find whole sections on every TV show that discuss climate change in there. And sometimes, you’ll actually have people use the fictional medium to express policy diagram disputes because they’re afraid that if they put it out on Twitter, they might get cancelled from Twitter, but you can have an alien of some crazy race make the argument in a science fiction story, and you can discuss those social and policy issues that you couldn’t otherwise. The Orville is a great source of those sorts of stories.
[Jamie Joyce]: First of all, I just want to say, Peter, oh, my god. Thank you so much. I’m so excited for TV Tropes. Thank you. We deconstruct film, but not television shows and non-documentary films. So this actually just may be a whole other source of media that we may really dive into, because I mean, we do archive memes, and we make memes available. So when you said pop culture, I was like, “Oh, yeah. We do the graphic image memes, for sure”. But I didn’t think about, yeah, an alien on a sci-fi film making a critique about something. Didn’t think of that. Thank you very much, Peter. And then as for your other question. Yes. But we have to be careful with labelling. Because labelling is very much a matter of fact and we don’t want to make a mistake and be incorrect about matters of fact. So when we label something opinion, or needs to be fact-checked, or no evidence provided, or this is cherry-picking or something like that, it’s because it is very easily associated with matters of fact. There’s a definition for a thing that’s commonly accepted. This meets a definition (indistinct). But when it comes to astroturfing, predatory journals and things like that, it’s more of a matter of argumentation. And so, we actually do model that in argumentation. So, for example, there’s this whole set of content from this one person who has published only in predatory journals, and we had to deconstruct the website and essentially build out all the argumentation about how the data is not verifiable, the journal in which it was published, it is not credible in these ways. But we had to model that as argumentation. And what we have to do, in terms of our responsibility, is just, we have to make sure when it’s visualised, they pop up at the same time. So it’s not buried, all the counter argumentation that suggests this is invalid it’s, “Hey, because of the severity and weight of the argumentations, they get this other data, you need to see these things at the same time”. So, yeah. We do that. We do our due diligence and look on those lists of suggested predatory journals. And then we check out the website. Did the website, essentially, say it’s pay-to-publish? Do they have no peer review? Do they have no editorial board? Essentially pick it apart. And then, make sure that, that metadata express through argumentation. Essentially saying this is invalid or, you know…
[Peter Wasilko]: And it also can be subtle, for this person might have a gorgeous new office in the Pfizer wing of his school and be publishing strong arguments in favour of Pfizer’s latest designer drug. And then, you’d wonder if he did a study that was designed to be able to find problems with that drug, would his school still have the funding to build that building? Or would he suddenly find that the primary source of his salary has gone away? And that might be influencing the way he structures his science. There’s also a community, I think it’s called ‘Tea’†, that’s looking at reproducibility in science, which you might want to have a look at, if you aren’t already familiar with that work.
[Jamie Joyce]: There’s a whole bunch of people working on the reproducibility issue. But what are they called?
[Peter Wasilko]: ‘Tea’, I think is their acronym.
[Frode Hegland]: Since we started a bit late, we will do a few more minutes. And, actually, Fabien, you go first.
[Fabien Benetou]: Just to bounce back, I also posted on the chat a book on agnotology† and the study of political ignorance. I really warmly recommend it. I say warmly even though it’s a horrible thing. But I think it is important. It’s very exciting to hear the process you’re going through. And that prompted me to wonder. So, what I did at some point was, I gathered most of the links of the articles whatever random pages I read. And I put them on my wiki. And what I did was the opposite. Meaning that I have a plugin from the browser that says, “Oh, you’ve already read that page, and that page is on that topic”. So I can browse back to my own notes based on what I’m seeing on my browser, on my screen right now. And I’m wondering if that could, also, be a way, because it sounds like your process is very thorough and could be practical behind, quote-unquote, just the map itself. But on your normal browsing session, being able to connect back to the map, for example. So I’m wondering if you’ve done that? Or if you believe that could be useful to browse the web? And then, as you go through a document, a piece of information that you already analysed, and it’s already referenced, if we could link back and browse the map at a certain point? I’ll do a bit of promotion for the book I put in the chat, in the meantime. If you’re wondering about the tobacco industry, alcohol industry, and oil industry too. Different sales(?) of Nobel prizes on topics that we’re not necessarily familiar with. And that you see the same heads, that’s a great book. That’s an extremely sad one, but you see the history of convincing people that don’t actually have the expertise but still have the intellectual prestige. So, yeah. Very valuable.
[Jamie Joyce]: Okay. So, yeah. Short answer, yes, we’ve been thinking about that, Fabien. One of the new tools that we want to build, actually, is going to be a web annotation system. So that people can go all the way through the chain of us collecting content, extracting it. You saw the spreadsheets where we copy things over to text and then deconstruct from there, that’s really lovely because if linked to those things people can see the exact line. But it would be lovely if it was just native. They can go to the archive.org website and see we’ve highlighted this and here is. And then, having that as a plugin that other people can go and traverse and just opt in to see, “Has the Society Library pulled this out?” And seen this somewhere, and implemented this somewhere, is definitely in the timeline of things that we want to incorporate, for sure. Not possibly yet, but yes, we’ve been thinking about it. And here’s the other thing too. I don’t have a huge amount of hope for integrating with Twitter and Facebook and things like that, because I know a lot of friends of mine, who created great products have not been able to get through the door. But that could be a thing too, also, let’s say, if there was a way of detecting the semantic similarity of a tweet with a Society Library snippet. They do this with Wikipedia on YouTube for example. There’s a particular topic with the, “Here’s the Wikipedia page on it”, in like a bar underneath, to try and promote people going to a source that YouTube finds to be substantial, in order to look and research into that more. And then, it could also be such that, journalists could reference our databases, and essentially, cite it in their news articles and people could link out to go see the Library. So it’s in the creation of new content, it connects to the Library, and then, the Library can also backtrack to, this is where we derive the claims that populate this library in other media content as well. And that’s just web annotation of plugins and things like that.
[Frode Hegland]: So final for me, anyway, is the work that I’m doing with my basic software, Author and Reader it’s bizarre. It took me two hours to see how it kind of connected with this. I think it’s probably because what I’m doing is so insanely much simpler than this. But the reason I want to highlight it to ask you a question is, in Author, which is very much targeted at students, part of the writing is for them to define things. If it’s important for them, write what it is. So you would write something like, Doug Engelbart and then a definition. In my case I would write, Doug Engelbart was my friend blah, blah, blah. So it’s personal. It’s not pretending to be objective truth. And then, maybe I’ll mention SRI. If I then somewhere else write SRI, when I then go back to the map, and I move anything I want, click on Doug there will be a line to SRI, purely because the text mentions it. Nothing fancier. But the reason I’m highlighting it to you is that you have this incredibly rich environment, it’s simply that, it seems that, if you make people define things, it helps their own thinking. And if they can then see how they connect. So I’m wondering if you can have a layer within the work you have, or maybe, I’m throwing a 10 million dollar research project at your hair, so I’m not realistically saying, do it now. But you go through this knowledge environment. You pick things up. And you say, “Well, I think this is bullshit, or I think this is important, or I think this relates to…” Whatever it might be. But in a separate space, so that after a while, when they keep doing this, they get a better insight into their heads. And I can see Mark and Antoine making all kinds of head movements because I know it’s related to their work. But I’m wondering if you both have a brief comment and then we need to wind up.
[Jamie Joyce]: I’ll just say one thing is that, what you express reminds me of some exercises we do at the Society Library when we teach students about having them extricate what is meant and claims, it’s not the same thing in terms of defining things. But it is an exercise. And I will just say that the feedback we get from students, from performing logical deconstruction exercises pulling out all the claims and media, is that we’ve heard many times that, by the end of the semester they gain a new sight. Because they just inherently see the density of language in a way that they didn’t see it before. And it’s really lovely because so many of them get so excited, and they come back and volunteer for us. They’re really enthusiastic about what they’ve learned, and they find it to be very valuable. So I think that an exercise like that could also be very valuable just based on the feedback we get from our exercises, which are not the same, but similar. And then, what you expressed reminded me of is that, I just had the thought just now, of a new kind of exercise where students could be compelled to be presented an argument, and then counter-argue with it, and then they can also see like how the Society Librarians actually steel man that argument. So they could work through the database only seeing partial pieces. And are doing their own research and counter-arguing. And then comparing that against the professional version. And maybe it’s better, maybe it’s not better. And that could help refine their thinking, as well. So, yeah. I think that those types of exercises really do help people with critical thinking. And I think just increasing their epistemic literacy, as well. Just really knowing how many assumptions that we pack in, to our everyday expressions, and understanding. And we’re forced to extricate that by defining or deconstructing. We really start to appreciate the density and complexity of meaning in knowledge.
[Frode Hegland]: Fantastic. I mean, Tools for Thought is part of this big thing. Marc-Antoine, was that your hand or was that a little mouse?
[Marc-Antoine Parent]: That was me. Sorry, I’m going to diverge a bit. And this is my thinking, not the Society Library. But the definitions, as you put it, is fundamental and what you’re doing, Frode, is helping encourage people to do their local contextual definition. And Jamie’s tool and work certainly does contribute to identifying specific definitions and work. And what I’m currently most interested in is these, how to assemble social definitions from individual definitions? And how to identify how they relate? Where are the differences? Including in emerging concept conversations. In some conversations, the concepts are emerging, the definitions are being negotiated, and evolving, and renegotiated. And this is where the ability to show the relationships between the concepts is extremely important. And when I say show the relationship, and that’s another thing I wanted to say to you, I think that the ability to qualify links is primordial. Bruno Latour, who’s a historian of science, has said that erasing the nature of links is one of the great crimes of 21st-century thinking. Saying these things are related. How? Doesn’t matter. That is absolutely terrible. Understanding how things are related is really key to a certain precision of thinking. And having a good epistemology and ontology of how things are related, I think is absolutely fundamental. And how things change when you push them from one domain to another, that’s Latour’s work. When you shift from one definition to another is when there are these shifts of meaning, which are necessary, they’re not always bad. Some of it is confusion, some of it is fluidity. But you need to be able to identify it. and that means naming the relationship.
[Jamie Joyce]: Yep, I just want to quickly say because this may be relevant to everyone else, the conversation of definitions has come up in communities that Marc-Antoine and I have both been in. And you may all find this to be very interesting that the Society Library approach definitions are also descriptive. So, for example, when we actually create definitions, we can disambiguate them for the situation. Which is really important in the data architecture. But also, we only give definitions to things that aren’t heavily contested. So the definition of climate change, for example, in the Society Library database, there are 19 different definitions. That’s because it’s such a common phrase, that’s actually just a zip file of 19 different files. It’s the same name for 19 different zip files of meaning of what people apply when they’re using the term. So when it comes to modelling argumentation you can’t just say, “Okay, climate change”. Because so many people are just going to come to that and interpret different meanings. So, we’ve had to find different climate crisis, this is a little bit different than catastrophic climate change, this is a little bit different than global warming. All these different things. And then we’re just going to have to get to the point where we start creating new names. Like the climate change hoax. All these different small differentiations to let people know that we’re not talking about climate change in the same way at all. So for us that is actually a debate. Our primary question within the climate change database is: what has changed? And there’s 10 different arguments about what climate change actually means and entails and the evidence that support that it’s derived from different media sets, etc. But many of the definitions that are not contested like, what is the Diablo Canyon Nuclear Power Plant? Oh, it’s like a double loop Westinghouse, blah, blah, blah. That’s not really something people argue about, so we just give it its definition.
[Frode Hegland]: And on that bombshell, thank you very much, Jamie, and everyone else. And we’re here every Monday and Friday. I look forward to having this transcribed, will take a while to organise and clean it up. And continue the dialogue and make amazing things happen. In this community, we’re looking forward to doing some sort of, a flatland, which is what we call, what we’re on now into VR environments. And back again a demonstration of the Future of Text at the end of the year. So it’s very interesting to have the insight, knowledge, and questions from today, and hopefully, some degree of dialogue collaboration. Have a good weekend everyone.
Jamie Joyce: Thank you all so much for your time. Thanks for having me.
Phil Gooch product presentation of Scholarcy
Video: https://youtu.be/pdVHOoh-EL8?t=899
Transcript
Presentation
[Phil Gooch]: My name is Phil Gooch, I founded a company called Scholarcy about three years ago. But my interest in interactive text goes a bit further than that, mainly through the field of natural language processing, which is what I did my PhD in. And really, I was trying to solve this problem that I had when I was doing my PhD, was that, discovering new materials to read wasn’t a problem. I discovered lots of papers, lots of resources, I downloaded folders full of PDFs, as I’m sure you all have sitting on your hard drives at home, and in Google Drive, and in the cloud elsewhere. So I had all these documents I knew I needed to read, and I wanted to try to find a way of speeding up that process. At the time, not necessarily connecting them together or visualising them, but just really pulling out the key information and just bringing that to the forefront. So I started building some software that could try and do this. And what emerged was something called Scholarcy Library, which I will show you now.
Scholarcy Library is like a document management system. You upload your documents, and they can be in any format. They can be PDFs. They can also be Word documents, they can be PowerPoint presentations, they can be web pages, they can be LaTeX documents, they can be pretty much any format. And what it does is, if we look at… This is the original PDF for one of the papers that I’ve got in my system. So this is a typical PDF, in this case, it’s like the original author manuscript that’s been made available ahead of time, as the open-access version of this paper, if you like. And as you’re obviously familiar with PDFs that aren’t created in software such as Liquid, Author that Frode has built, most PDFs don’t give you any interactivity or anything at all. You can’t click on these citations or go anywhere from here, for example. So the first thing I wanted to solve was if I bring this into Scholarcy, what does this look like? The same paper. Well, the first thing it does, is try to pull out what is the main finding of the study and it brings that to the forefront. The other thing that it tries to do is take the full text and then make citations clickable. So you saw in the original text, the original PDF, that citations aren’t clickable. So my first goal was to make citations clickable. So I can go on to that citation and go straight to that paper, and then read that, or pull it into my system and link it together.
So that was the first goal. And then, the second goal was, well, once I’ve broken this PDF down, can I do things like extract the figures and so on, and again, just make them first-class citizens so I can zoom in on them? And that was the other goal. And this all really then turn into a process to turn documents into structured data. And so, what I’ve built was this back-end API, which is freely available to anybody. It’s in the public domain. It’s not open-source code, but it’s an open API, so anyone can use it. If you go to api.scholarcy.com there are a number of endpoints here, which look a little bit esoteric. So there is some documentation on this on GitHub. If you go to scholarcy.github.io.slate there’s a whole bunch of documentation on what this API does. But essentially, what it does is, you give it a document, such as a PDF, but it doesn’t have to be PDF, and you upload it, and it basically turns it into JSON. And as you know, once you’ve got JSON, or you’ve got XML, or any structured data, then you can pretty much do what you want with it. So what it’s done is turn that into JSON with all the information broken down into key-value pairs. So you’ve got a key for the references and you’ve got all the references there, you’ve got a key for the funding group that has been broken down. So once you’ve got structured data, then it’s quite easy to bring it into this nice interactive format like this, where everything is, kind of, hyperlinked and clickable. So we can go straight to the study subjects and so on and find out there were 16 people involved in the study. And then, we can deal with things like, what were the main contributions of the study, and we can just scroll down, click on one of those, and it takes us straight to that finding. So the idea was really, I suppose, not really to cheat, but to, basically, speed read this paper by highlighting the key findings and making them clickable, as we made the references clickable. So all this is in the JSON data that’s underlying all this. And then it makes it more interactive, basically. So that’s the goal.
That’s all well and good, basically what we’ve done is turn PDF into an interactive HTML with clickable citations and expandable and collapsible sections. But obviously, you want to deal with more than one paper at a time. And so, what I looked at doing was building something that could turn this into linked data. Now, I didn’t want to build a new piece of software like Noda, or a triplestore, or anything like that. And so I found that the lingua franca for a lot of new tools that try to connect stuff together is this format called Markdown. One of the tools I use for hosting Markdown, and you may be familiar with it, is called Obsidian. But there’s many tools like this there’s Roam Research, there’s Bear, there’s Logseq, there’s a whole bunch of tools, I’m sure you’re aware of, that handle Markdown data. So here is that same paper that was once a PDF, now in Scholarcy. But now we can export that to Markdown, and we can do this one at a time. Or if I really want to, I can export all of them in one go. So I’ve only got four here, but I could have 400. Export them all in one go as Markdown and then I can load those into Obsidian. Put that in my Obsidian library, and when I open that in Obsidian, it looks like this. So it’s the same data but now it’s in Markdown format, now it’s editable so if I want to, then, edit the Markdown in here I can go away and start doing that and visualise it. But now we’ve got the same information along with all the other papers that I had in my collection that were also converted to Markdown using Scholarcy. I can connect them together.
So, I’ve got some of the key concepts, if I click on one of those, then it shows me other papers in my collection, like this one that also talks about functional connectivity. I can go straight to that paper, and then, I can see the main finding of that study, and I can see other things that it talks about, like the medial prefrontal cortex, and I can see other papers that talk about that. As you can see we’ve got this network graph going on, but it’s, kind of, embedded in the text, I can read the papers I wouldn’t have before, and I can view all the figures and zoom in on them. But they’re in this Markdown format where you get all this linking for free, which is great. And in common with other tools that handle Markdown, you can do these visualisations, so it’s going to show me here, if I could click on this graph view, how these papers are connected, in this case, by citations that they have in common. But if I really want to see all the concepts that I have in common, then I can click the tags view, and then suddenly you’ve got all these green nodes here that show me where all these papers are and how they’re connected by their key concepts. And as you know, Mark and I were discussing, just before this session started, the issue that you’ ve got too much information. This becomes a question of: What do we do with these kinds of visualisations?
And I’m sure many of you here will have suggestions and ideas about how to deal with this because once you’ve got more than 10 or 20 papers, these kinds of visualisations become a bit intractable, but Obsidian lets you do that kind of graph analysis, can write queries and so on. Which I haven’t really done much with, my background is not, at all, in visualisation, it’s in NLP and converting documents from one format to another. That’s been my motivation in building this, is being able to turn documents from PDF into Markdown or other formats. And that’s what Scholarcy does. It’s a document conversion software, it’s a summarisation software, it gives you the key highlights of the paper, its objectives, methods, and results. It pulls all that automatically from each document using NLP and deep learning and it makes it interactive. But it does also extract into these various different formats. And one other thing it tries to do is to show you how the paper relates to what’s gone on before.
So, when an author has talked about how their work sits within the wider field of research, Scholarcy tries to pull out that information and highlight it so it shows you where are some potential differences with previous work, and who’s talked about that, in terms of, counterpointing with what this author is saying, and again, we can click on that and go straight to that paper if we want to. Or which studies does it build on, for example. Does it build on a study by these guys? How is it different? So it’s pulling out all those citation contexts, and then classifying them in, is it confirming, is it contrasting, is it just building on it, how does it relate? It doesn’t always get it right, but most time it gets in the right ballpark and it just gives you that extra context. And again, just making that information interactive. I guess the next step is: What more could be done with this data?
At the moment, it’s in the very two-dimensional view, either in Scholarcy as one paper at a time, or in Obsidian via a network graph view. But what else could be done with this data? And maybe some of you have some suggestions about how that could be visualised, perhaps using virtual reality or some other means. But really, the motivation for this was to make it easier for me to read all the papers that I had to read for my PhD, make it into a friendlier format that I could, for example, read on my mobile phone. This tool called Obsidian has an iOS app and I can actually read this paper in a nice friendly format that will be responsive, including the tables, because Scholarcy also converts the tables in the PDFs to HTML. So I can get all that data out as well and read that on the go, which was the goal of doing this, really. So that’s Scholarcy in a nutshell. It exports to various other formats as well, so if I really wanted to export my paper, imagine this was my own paper and I want to export it to PowerPoint, I will turn that into a presentation. That is one thing I did do with the chapter of my PhD, was turn that into a presentation. I could just export this as a PowerPoint slide deck, and it will summarise this paper and distil it down into a series of slides. But that is the goal, really, is to be able to convert and switch between different formats without having to worry about whether did it start off as a PDF, or was it a Word document, or was it something else? Really, every document gets turned into this standardised format that we call our summary flashcard, where it’s got that same structure. I was hoping to show you the PowerPoint export that doesn’t seem to be playing ball today.
So that’s basically, in a nutshell, I mean there’s a free demonstrator you can try out because we do have a number of free tools including the reference extraction component that Frode was alluding to earlier, that links all the references together, and that’s a freely available tool. And so is this. If you want to try this out with any document, you just upload a paper and it does exactly the same as what I showed you in the main document management tool, but it’s just one document at a time. You can load a paper and it breaks it down into this flashcard and then you can download that in Markdown if you want and then visualise that with all your other documents. So there’s a whole sequence of other tools, as well, that we have, but this is the main one. It’s what we call our Flashcard Generator.
So, yeah. That’s it, really, in a nutshell. Let’s maybe bring it into a discussion and get some feedback, really, because it’d be good to know about how we could take the structured data and do something else with it other than put it into Obsidian, or Roam, or other Markdown-aware tools. Maybe there are some more interesting things that could be done there. So, I’ll pause at this point.
Discussion
https://youtu.be/pdVHOoh-EL8?t=1768
[Frode Hegland]: It really is a nutshell, and it’s just amazing what you have done. And you presented like you’ve done a few Lego blocks, and that’s about it. It’s just a British understatement. But there’s one thing before we’re going to proper dialogue I’d really like to see more of. And that is the bit where you come across a citation in a document and you can click on it to find out, to put it crudely, its value or relevance. Would you mind showing that? Because when you do these big graphs, where to go next is always a huge question and I think this, navigationally, really helps.
[Phil Gooch]: Sure. So, let’s look at that same paper that I was looking at earlier. If we’ve got a citation, we can mouse over it and we can click and go to that paper. But in terms of what is the value of this citation, we’ve partnered with another start-up called syte.ai, that you may be familiar with, and what we can do is show the statistics that sites have gathered on every citation. And I think we’ve got a huge database now, we’ve got about a billion citations. What this shows me is how many other people have, not only just cited this study but how many people have agreed with it. So this had about 1,258 citations, but of those, 18 have been confirming the results of this study. What that means is if I click on that link there, it’s going to give me some more background. Here’s the paper by Stam that this author cited here. And we can see that it’s got 18 supporting citations, and three contrasting. Let’s see what that means. It basically means that they’re saying things like, “Our results agree with previous studies which include Stam, and so on”. Consistent with this guy, for example. Basically, 18 of these citations are ones they’re all saying, “Yeah, we found something similar.” But three of these, they found something different. So what do they say? Well, we can just click on that. So, previous studies, blah, blah, Stam. Looks a bit ambiguous to me, not sure if it’s definitely contrasting or not. This is the thing with machine learning, sometimes you don’t get it quite right, and it’s a bit borderline if it’s actually contrasting. But you can see that, again, the context in which the other people have cited this study, that these guys have also cited it. Were they positive about it? Or were they negative? And so, syte.ai is a really cool tool for showing you this context about how everyone else has talked about this paper. So, for example, in this paper here, we could find out who else has spoken about it. Because these relationships go in two directions, we want to know what this paper is saying about other people’s studies, and what other people have said about those same studies. But also what other people say about this study itself that I’m reading. If I click on this link here, it should take me to what other people say about this van Lutterveld paper, and we can see that actually people are a bit neutral about it, there are 31 citations and they just mention it, but none of them are contrasting, and none of them are supporting. They’ve cited it, but they haven’t really said anything positive or negative about it. So syte.ai is a really cool tool that just lets you explore those citations. And we link to it as a matter of course. So every citation in here should have a button where you can see those stats. And then the other thing we try and do, and this doesn’t always work is, say, “Well, rather than going, looking, and reading all these cited papers, can we just get the gist of them?” We have a little button here that will go and find each of those papers and it will just do a quick summary of what was done in that paper and then we can see. It’s like a subset of the abstract, effectively. What was this paper about? Is it something that I’m actually interested in going and reading more about? If I am then I can click on it and go and read it. So the idea is to bring all that information, from each of those studies, into one place, either with citation statistics from the site. Again, this looks like a reliable study, 13 people have supported it, so that looks good. But what did it say? And again, we can just click the findings button here and it will go and try to pull out what the study found. And there are some of the findings there. So that’s another aspect of what Scholarcy does, that citation linking and classification.
Dialogue
https://youtu.be/pdVHOoh-EL8?t=2093
[Frode Hegland]: Question to everyone in the group before I do the hands up thing. how amazing is this? It is absolutely amazing, isn’t it? And also, the way that Phil works with other APIs from other services. The way these things can link together is just so incredibly amazing. And I don’t think most academics are aware of it. Because you’re the newest in this session, Ismail, please you go. And then, Peter.
[Ismail Serageldin]: Thank you. You probably are very familiar with the work of David King and a few others at Oklahoma State. I was quite interested in their work a few years ago, because they had done hermeneutics of Islamic and Quranic work on 12,000 things. Phil, you had this diagram with all the nodes connected with the greens, and you said, "Well, where you go from here?" It all looks pretty much like one big tapestry. What struck me about what David King was doing at that time was that, they were able, and this was really stunning for me, able to put all the authors and then, surprisingly, the graph tended to group authors together. So, all of a sudden, the group of these Israelite debaters, back in the 10th century were all in one part of the graph, and all the Ash'ari were in another part of the graph. And the schools of thought, somehow, emerged out of that. So it didn’t look exactly flat, like the diagram. Based on the diagram of this thing, they were able to group them into, maybe the citations, maybe other things would be able to assist in that, but if it did that, then you might see schools of thought emerging in the pattern in front of you.
[Phil Gooch]: Yeah, that’s great. I think there’s a huge amount like that, that could be done. So that network that I showed was in another tool, in which I’m not involved in, it’s called Obsidian. And I’ve just put a link to it in the chat. So it’s obsidian.md. And that is just the tool that allows you to visualise these relationships. It’s quite basic, and it doesn’t show, I don’t think it can show those levels of annotations that you mentioned that David King showed, where he had the authors, and so on. But there are other tools that do a bit more than this, along the lines of what you’re suggesting. And one is called Connected Papers, which I’ll put in the chat, where they do try to find out similar schools of thought. The idea is, you put in one seed paper and it will find other related papers, not ones that are related by citations, but also similar themes. I will also quickly share my screen to show you. And I think that, what they’re trying to do at Connected Papers, is trying to generalise what you were suggesting, what you’re talking about with David King, where they show, here they’ve got the authors for a given paper and what they’ve tried to do is show related papers where, maybe other people have cited them together in a group, or they’ve got similar themes. And so you can click on each of those and find out more about them, and you’ve got the abstract and so on. And there’s another one, there’s quite a few tools like this, there’s one called Research Rabbit, which is pretty cool, but unlike Connected Papers, it only works if you’ve got an academic email address, which I don’t have anymore. But those of you that have, you might want to check out Research Rabbit because that tries to do that. So in answer to your question, Ismail, there are other people doing those visualisations and trying to generalise them. It’s not something that I’m going to do myself. My role, really, is just to build tools that do convert from one format to another, so that other people can do those visualisations. But, yeah. I think it’s a great suggestion. And I think the potential hasn’t really been fulfilled of all this visualisation and linking yet. Partly because, when the data sets become large, it does get hard to then keep track of all these nodes, edges, and what they mean. I think, Mark, you’ve done some work on this with citations, showing things about who’s citing it and who cited it by, looking at alternative ways of doing it, other than a network graph. But I think there’s still room to come up with some new type of visualisation that would show all those relationships in a compact way. But you guys know more about the people that are doing that and me. I’m an NLP person. I’m not a visualisation person. So I’d love to hear more about those that kind of work.
[Peter Wasilko]: I was just wondering, have you received any pushback from any of the Scholarcy publishing houses complaining about your personal document?
[Phil Gooch]: No, because I think… That’s a good question. We haven’t had any complaints because we’re not making those converted papers publicly available. So it’s a tool like Dropbox or Google Drive. You drop your papers in, you’re the only person who has access to those condensed versions of those papers, those interactive versions of papers. We’re not putting them out there in a massive database that everybody could access. So, no one’s complained about copyright breaches because it’s really only for personal use. But I think there could be a lot of value in taking every open-access paper and putting it into this kind of structured format and showing how they’re connected. And I think, if we were to do that, then, yes, publishers would complain. But we are in discussions with some publishers about, maybe, doing it on a subset of their papers, in some way. But it’s just a question of priorities. There’s only me and one other person working on this at the moment. So it’s about where do we spend our time, and publishers are a bit of a distraction at the moment for us. So we’ve had one or two conversations, but yeah, they haven’t complained, basically, is a short answer.
[Peter Wasilko]: Ah, that's encouraging. Also, have you taken a look at the bibliometric literature?
[Phil Gooch]: The bibliometric literature? I’m familiar with some of it. But not massively, no. I know there’s lots of stuff about the whole open citations, thinking about making every citation open. There’s the open citations initiative, but did you have something in mind, particularly?
[Peter Wasilko]: Just that there’s like a whole subset of the information retrieval literature looking at co-citation relationship and term clusterings amongst society documents. And also, there’s a whole sub-community that’s been poking at those statistics for quite some time, and you might be able to find some useful connections there.
[Phil Gooch]: Yeah, I’ve talked to a couple of people. There’s a chap called Bjorn Brems, and there’s also Bianca Kramer and David Shotton, who’s in the open citations initiative. I’ve had a conversation with some of them. We’ve actually created an API that some of them are actually using within open citations, I’ll just put it in here, to extract references from papers so that they can be connected together. Because one issue with citations, although it’s not so much of an issue now as it was, was that these citation networks were not freely available, publishers weren’t making them available unless you signed up to Web of Science or Scopus. But now more publishers are putting their citations into Crossref, so that people can do those kinds of network analysis that you mentioned. But we’ve also created this tool that other people can use, authors can put their own papers in there or pre-print, and they will extract the references and then they can be used. Some of the people at open citations have used this API to do some of that extraction. We’ve made that freely available for anyone to use as much as they want until the server falls over. It’s not on a very powerful server. But, yeah. There’s a lot of work going on in this, but it’s not something that I’m personally involved in. I focus more on the data conversion side, and then, once that data is converted, I like to give it to other people to actually do the analysis, if that’s what they want to do with it.
[Peter Wasilko]: Also, have you considered applying your tool to bodies and source codes like, throw to GitHub and look at all of the citation relationships that actually take the form of code inclusion?
[Phil Gooch]: No. It’s a great idea, though. No, I haven’t done that. That could be a good project.
[Brandel Zachernuk]: This is a really cool tool. I’m really excited by the idea of rehydrating things that are essentially inherently already in hypertext and just making them navigable in the way that they should be based on that conceptual content. In terms of suggestions or questions about further directions, the main question that I would have is what drives my work, so it hopefully doesn’t come across as offensive: What is the point of the functionality? What are the intentions that people have that they follow as a result of using the system? And in particular, when somebody is good at using the tool, what are the primitives that they establish mentally and procedurally that drive their behaviour and action within it? And then beyond that, what are the ways in which you can render those primitives concretely in order to make sure that the use of the tool intrinsically lends itself to understanding things in the way that an expert does?
So, right now, you have a lot of things in it that are useful, but they’re not especially opinionated about what you do with them. And so, the suggestion I would have and the question is: How do you ramp up that opinionation? What are the ways in which you can, more strongly, imply the things that you do with the things and the way to read the specific things? So there are numbers, like the confirmations and address become the contrasting results and things like that. What do those mean and how can people understand those more directly, if they need to? One of the things, as these folks have heard me bang on about, I am not from academia, so I’m not familiar with the sort of, people’s relationship with academic papers and what people spend their time doing. Something that I have spent time in, within the context of academia is, debugging my friend’s prose. So where is (indistinct) in neuroscience, and I’m sure it’s not peculiar to his discipline, but you can end up with an incredibly tangled prose, where it’s, essentially, trying to do too many things in a single sentence, because there’s a lot to get through. And the sort of approach that I take is very similar to… Have you ever heard of visual syntactic text formatting? It’s a system of breaking sentences and indenting on prepositions and conjunctions. Oh, you built it into Liquid (Author)? Right. Yeah, you did too. And it’s basically taking something more like code formatting and turning something that I think is pretty generally the case to academic text, that it can end up pretty hard to read. And so that it allows you to follow individual ideas, and understand the regards in which they’re nested and indented through that.
So, I guess, what is the hardest stuff to do with these academic texts? And then also, potentially, I’m sure you’ve read and reread “As We May Think”, Vannevar Bush’s book, paper, column, article in 1945. Have you read it before? In large part kicked off the idea of computing for everybody who does computing. And it was made by the man who was responsible for the National Science Foundation during the American War Effort. And he was then complaining about the impractically large body of knowledge that was being produced year on year. And needing some memory extension that would allow him to navigate all of the, I think, academic papers, be able to create hyperlinks between them, and have some kind of desktop environment for doing. It’s a really wonderful read, because he’s basically describing the modern desktop computer, except built out of gears and microfiche, because that’s what his mind was thinking of in the 1940s. The reason why I bring it up and belabour the point is because one of the things that were really wonderful about Bush’s conception of it is that, the navigation of the information was just as important as the information itself.
So one of the things that I would be really curious with is, in terms of somebody’s use of Scholarcy to navigate the Docuverse, what are the artefacts that might be kind of re-rendered themselves about somebody’s consumption and processing of a series of documents? Because it strikes me that the browsing interacting behaviour that somebody engages in within the context of your system and framework that you have set up, could itself be a valuable artefact. Not only to the individual doing that navigation, but potentially to other people. Bush envisioned people being trailblazers, constructing specific trails for other people to navigate. Where the artefact was solely the conceptual linkages and navigation through those specific documents, which I think is something that Google essentially is able to leverage in terms of making page rank. But most other people don’t have access to it. But your individual trip, and the traversal of people, actually, between pages is one of the major indicators of what are going to be good Google search results. They have the benefit to be able to make use of that data, whereas other people don’t. But in your case, because you are particularly interested in the individual, the user making the connections, and drawing it between that actual browsing history, and navigation through specific things, it strikes me itself as a very useful artefact to see what people have missed, what people have spent their time on, and things like that. But, yeah. Really exciting work.
[Phil Gooch]: Great. There are some really great questions there. To answer them briefly, the first motivation and use case for this was my own need to understand the literature in what my PhD, which was in health informatics. So the actual idea of linking all this stuff together, at the time, wasn’t there. It was, actually, can I break this single paper down into something I can read on my iPad without having to scroll through the PDF in tiny print? Can I turn this PDF into interactive HTML? So it’s really much focused on, what can I do with individual papers to make them easier to read and digest? And what we started hearing back from users was that, actually, particularly novice users, novice academics, I should say, most of our users are people doing master’s degrees, or maybe in the first year of their PhD, where they may not be used to reading academic literature, and it takes them a couple of hours or longer to go through a paper and figure out what’s going on. People tell us that it helps them reduce the time by, as much as 70% in terms of understanding the key ideas of the paper and just being able to follow up on the citations and the sources and so on. That was the prime motivation, just to really make the reading experience easier. And, in fact, as recently just at the beginning of this year, we’ve been awarded the status of assistive technology by the U.K. Department of Education, because we’ve got a large user base. People who have dyslexia or attention deficit type disorders, where they have specific needs, they’re in university and find it’s hard to deal with an overwhelming amount of information in one go, and they really find it beneficial to have it broken down. And there’s a lot of research on this, in terms of, generally, why students don’t read the literature that they’re given by their lecturers or by their educators. They enrol on a course, they’re given a long reading list, and then, they have a lecture, and they go to the next lecture, and the lecturer says, “Okay, who’s read the material?” And most people haven’t. And educators have been tearing their hair out for years trying to figure out how do we encourage people to read. And there’s some research on this about what will encourage students to read, and basically, it’s: break the information down, make it more visual, make it more interactive, highlight some of the key points for them. Just give them a bit of hand-holding, if you like. And so that’s what the technology here tries to do. It provides that hand-holding process. But in terms of the linking of everything together, that’s a bit of a late addition, really, to Scholarcy. And it was really motivated by the fact that, I noticed there was a big academic community on the Discord channel for this tool called, Obsidian, where people were saying, “Well, how can I incorporate all these tools into my research workflow?”
And the big need that most researchers, or most students, anything from masters level onwards, the big tasks they have to do is, they have to write a literature review that justifies the existence of their research. What have other people said about this topic? And then, when you write your thesis, or you write your essay, you’ve got to say, Well, all these people said this. This is my contribution." So the task of doing literature reviews is an ongoing one that everybody, every academic has to do. And so we wanted to make that process easier. Once you’ve got those papers that you’re going to write about, drop them into something like Scholarcy, and it’ll break them down, and you can export them into a tabular format. So, one of the things I didn’t show is the export of everything to this, what we call, a literature review matrix in Excel, where, basically, you have about 100 papers say in your review, and you want to compare them side by side. That was one of the other motivations for building it. It was to do that side by side comparison of papers, which I can quickly show you, actually, while I’m talking. So, yeah. Writing literature, some people in academia, there’s this whole department that is just writing literature reviews. So if I’ve got all my papers here, and there are 26 of them in this case, what do they look like side by side? So, in Excel, here’s the raw format, I’m just going to make that a table in Excel, and then, what I can do is just make this a bit bigger. And then, what I can do is slice and dice the information. Excel has this really cool functionality called slicers. So I can say, “Right, I want the authors as a slicer, I want the keywords as a slicer, and maybe the study participants”. And so, what we’ve got now is able to slice and dice these papers according to their keywords. So most academics are quite familiar with tools like Excel. Let’s just look at all the papers that had 112 individuals or 125 participants, for example. And we can just show those. Or look at all the ones that are about cerebral palsy or DNA methylation. So we can do that quick filtering of papers and compare them side by side. And obviously, I can make this look a bit prettier, but the key idea is being able to filter papers by different topics or by numbers of participants, for example.
We typically want studies that have a lot of participants, and ones that only got eight subjects, for example, maybe aren’t going to be as useful to us. So that was the other motivating factor and this is how people use it to help with their literature review. So the whole thing about linking everything together, as I showed you in Obsidian, is a relatively new development if you like. And so, yeah, I’m open to hearing about how people might use this. At the moment I don’t think many people are using it for this kind of linking. They’re mostly using it for reading, and they’re mostly using it for creating these matrices that they then use to help figure out the literature and what’s going on. For example, you might say, “Well, I’m only interested in papers that have open data availability”. So I can just look at ones that are non-empty, for example. So if I select all the ones that are not blank, then it filters those papers, the only ones that have got some open data available are the ones I’m going to look at. Or I might want to say, “I’m only interested in papers that talk about the limitations”. It’s quite important for studies that talk about the limitations, but not every paper does. So again, I can filter by the presence or absence of limitations. So this kind of literature review is one of the ways that people are using Scholarcy. But primarily as a reading tool or as a document ingestion tool. So for example, the other way I can get information in is, if I’m reading a paper for nature, for example, I want to get it straight in, while I’m reading it, I can just run this little widget that we built for the browser which basically will read, go away, read and summarise that paper for us. And then, we can click save and then it’ll save it to our library, so I’ve got that nature paper here. Again with its main findings, highlights, and everything. And I can do that with a news article as well. If I’m reading a page in The Guardian, I can click on my extension button, and again, get some of the highlights, key points and links to, you know, who’s Sophie Ridge, I can click on that, she’s a BBC journalist and newsreader, for example. So, it does all that key term extraction as well. And again, I can save that. So if I’m interested in news articles, then I can also use that. And then the other thing that people use it for is to subscribe to feeds. So you’re probably all familiar with RSS feeds, which seems to be making a comeback, which is great. So, if I want to, I can subscribe to The Guardian U.K. politics feed, and just put our asses in front of that. And then, if I go back to my library and say, let’s create Guardian politics, and put in that feed it’s going to go away and pull in those articles and turn them into that interactive flashcard format for me. And I can do that with a journal article, so I’m actually subscribed to a feed on neurology from a preprint server called ‘medRxiv’ and it’s pulling in each day, it’s going to pull in the latest papers. So it’s like an RSS reader as well. So people are using it for that. So, yeah. They’re mainly using it as an enhanced reading tool. And there’s a tool to help with literature reviews.
But the whole hypertext linking and things like that is a relatively new thing that we’re not quite sure how many people are actually using to create those relationships between things. While I was talking, it’s gone away and just started to put in those Guardian articles here. So, I put in Guardian Politics and already it started to pull in those articles here. It doesn’t just work with PDFs, it works with news articles as well. So it tells us more about Grant Shapps, he’s the Secretary of State for transport. People use it if they’re new to a subject. If I’m new to neurology, I want to know what some of these terms mean. We’ve got these hyperlinks to Wikipedia, so if the Akaike information criterion is unfamiliar to me, I click on that and it tells me what it means. I’ve got the Wikipedia page about it. If I don’t know what basal ganglion is, I click on it and it tells me all about it in Wikipedia. So that level of linking is something we’ve had right from the beginning and this is well used by people who use Scholarcy. But this kind of graph view is not really well used at the moment. And we’re trying to figure out how to make this friendlier, because we have to do this in a separate application at the moment. But the Wikipedia linking is very popular. So the basic level of doing those key concepts, and their definitions is certainly something that people use to get up to speed on a subject if they’re quite new to it.
[Brandel Zachernuk]: That’s awesome. In terms of the use of things like site linking to people and concrete entities like the basal ganglion, I would love to see in the direct adornment and representation of those entities within the document that you have as being reinforcing the category of things that they are. So, having a consistent representation, for example, of people so that you have, if available, a thumbnail, but otherwise some indicator that these things are definitely people, show them, rather than concepts. I saw that you have a little bit of, it’s being able to pre-emptively pull a little bit more information about what you’ll find behind those things. One of the things that I really love to do is make sure that people minimise the surprises behind clicks so that they have the ability to anticipate what kind of content they’re in for. And that helps frame their experience because hypertext is very valuable insofar as it allows you to navigate those things. But if it’s anybody’s guess what’s behind them, then that can be very distracting. Because it means that it’s difficult for them to process things in those flows. Another thing that I’m really excited by just looking at that, natural language processing lends itself incredibly well, it’s a question answer and agentive mediated action and stuff. Have you played with the speech-to-text and the text-to-speech engines within browsers in order to be able to create conversational agents and participants? And it strikes me as a lot of fun to be able to do, where you could actually ask pre-formed questions of a certain kind about your corpus, in order to be able to do things like that.
[Phil Gooch]: Yeah, that would be a great idea. I know there are some other tools. There’s a tool that does some similar stuff to what we do, it’s called Genei and they have a question answering thing. We haven’t done that kind of thing. But, yeah, certainly something we could add. Either you may type in a question like, “What is the best evidence that supports the use of this particular drug against Covid-19?” for example. And then, it would go and search all those documents and show you which ones generally support the use of that drug, for example. We could do that. And that could also be a speech-type interface. So, yeah. That’s something that we could add to it, certainly, as a future enhancement, that’s a great idea.
[Brandel Zachernuk]: The other benefit of a speech primary environment is that you have the opportunity to use the visual feedback as a secondary channel, where you can say “I’ve found these documents and they are here”. And then the documents are up here and things like that. But, yeah. It’s super cool. One of the things again that strikes me, that you’re doing with it, as well, is the academic paper format is very curious and very dense, in no small part, because it’s for shipping important information on (indistinct). And so, as a general concept being able to be a little bit more generous with the space, in order to be able to characterise and categorise the different things that are in a paper, is a really good viewpoint perspective on what it is that you're able to do. Because, like I said, even though an iPad is a smaller, in many regards, device than the papers that you’re going to be reading, or especially a phone, you do have the ability to renegotiate the space, the real estate that’s devoted to those things. And, yeah. Being even more generous with the space that you use to carve out the, this thing is this, that thing is that, might be a valuable way of playing with all of the different elements that you’re presenting.
[Phil Gooch]: Yeah, that’s right. That was one of the main motivations. To reduce that problem of squinting at PDFs on screen. Because they were meant for print. But everyone’s using them as an online distribution format, as well, which wasn’t what their intended purpose was. And so, just to try to transform that content into something that was a bit easier to read on screen, I don’t think we always succeed. And I think, actually, within the academic community, there is this, people are trying to move away from PDFs as a means of distributing knowledge, but people are still struggling to get away from that format for various reasons. Which is a subject for another discussion, perhaps. But, yes.
[Frode Hegland]: For a long time. But since you just talked about the provocative three-letter word, PDF. It is something we’re discussing here. We use it archival, and we accept academics use it, but as an intermediary in rich format, clearly, it’s not up to snuff.
[Mark Anderson]: Well, first of all, thanks so much. Fascinating to see Scholarcy again. It’s something I’ve been meaning to find some time to dive into again. Because it's interesting you talking about the Obsidian graph and things. So, for instance, one of the problems there is what it actually does. It shows you the links that you made. When I say you made, now this gets to the interesting part. If we begin to do automatic extraction, who made what link for what purpose, this is where we get lost. And there’s a massive, I mean, obviously, there’s Obsidian and Roam and there’s a whole cult around zettelkästen. But a lot of these things, unintentionally, is the ‘underpants business gnomes—the Underpants Gnomes business theory, where if you collect enough stuff, a magical thing will happen, and success at the end, and no one quite knows what the magic is. I think one of the interesting challenges, but opportunities, actually, to the data set you’re now sitting across is to be able to start to surface some of the relationships. The real privilege you have with the dataset is that you know what’s there, and you can begin to make more objective study comments as to what the links mean, that many people can’t. So some interesting, in a sense, research to be done there. So one way one could look and try and make sense about diagramming would be, to take an area that we know has been just really well trampled by people, so you might say, “Well, there are a few surprises in the literature”. And then play around with the visualisation.
Because you want to be able, to then, have something that’s otherwise really hard to do, saying, “Okay, I’ve made this wonderful-looking thing. Is it meaningful or not?” And most of the time we do this, we just don’t know. The main thing is we know it looks pretty. And that’s another problem because we like to make pretty and aesthetically pleasing graphs, whereas life would tend to suggest that the messier it is, probably the closer you are to the ground in truth. So I think that might be an interesting area to look at. I think, then, to make sense of what the either inferred or extracted hypertextual nature or linkage in the data is. It’s probably most meaningful to take, or most useful to take a bit that’s essentially well known for whatever reason. But one where there isn’t a great thing. So, don’t pick something that’s a great topic of anxiety, or social warfare at the moment. But I think that there ought to be places where we can see this. Which brings me on to another thought which is the degree to which I’m guessing that the sciences, the paper in the sciences are more tractable to this process than the arts. Because the language is, by and large, more direct. So we’ll talk about a thing, and that’s the thing that we can go and look up, whereas, in a more pure humanities side, the reference is just maybe elliptical, and did you have to know the subject matter quite well, to know that they’re actually referring at one form removed from the subject that’s actually under discussion. I think that’s just a state of where we are with the art, rather than a limitation, per se. But is it the case you get more back from science areas?
[Phil Gooch]: Yeah, that’s right. It does. For the reasons that you mentioned, the structure tends to be quite standardised. They have what they call the IMRAD format, Introduction Methods Results And Discussion. They’re very much about stuff that can be packaged neatly into facts if you like, or the factoids, or things that got some evidence about it. Well, we have tried using it on certain subjects in the social sciences, things like philosophy and biography, and well, I mean, literature generally, as you go towards the literature, and particularly fiction, it doesn’t really work at all other than the fact that we can pull out named entities from people and places and so on. But in terms of pulling out the argumentation structures, is much harder in the humanities. But interestingly though, actually some of the feedback we’ve got from some of the users is that, in a more social sciences subject, it does really well. And less well in things like philosophical and rhetorical-type articles, in the hard sciences, or the stem sciences. It doesn’t do very well in engineering. And I think the reason for that is a lot of mathematics, and we don’t really handle mathematics very well. Getting decent mathematics out of PDF is hard. And then often, an engineering or mathematics paper is all about the equations, and the discussion around it is maybe not peripheral but it’s secondary to the main maths and formula that you’re presenting and putting forward. So, yeah. There are some subjects that are harder to apply this kind of NLP to, and certainly, humanities is one of them, anyway.
[Mark Anderson]: I hope you’re mentioning it because I don’t share that as a negative at all, I was just interested to see how the coverage goes. Because another thing that occurred to me, in terms of, again, because you’ve got this fabulous rich data set, one of the things I always find myself worried about when I was doing the research was avoiding the Stalinist theory of art—because 81 people said this was really good, it must be good. And indeed one of the things in our PhD group in Southampton was discussing was actually a way that you could start, for instance, to classify what’s a drive-by citation. “Oh, I have to cite that because otherwise I get shouted at”. And that was, to my mind, a meaningless citation, because actually it’s been done for no real good intent, as opposed to the thing you actually genuinely wanted to cite because it actually added interest. And that strikes me as a challenge when doing this extraction, not because of the sin of commission, but you get to the next level. So, in a sense, do we need to start learning new ways to read this? So as a student or a user of this rich data set, what are the new questions I need to learn to ask? Because, to a certain extent, we arrive at this technology at the moment. Sort of, “Oh, look. This number is bigger than that number”. And we don’t often stop ourselves from thinking, yes, but is that a deep enough thing? There are some interesting angles to be played there as well. How one might tease apart some of the raw numbers which otherwise float up the surface. Because this is what I was thinking with bibliographies and these raw citation counts. Because maybe it’s just a field I was working but I don’t think so, that I was often surprised at how many times I went to a really highly cited paper, I’m thinking, I just don’ see what is so special about this. And even when I put in the context of what was known at the time, it’s still not special. It’s clearly being cited because it’s getting cited a lot. But no one has ever thought to say, “This actually isn’t a very interesting or useful paper”. And at a slight tangent, I’m interested to know what do you see as an edge, as to how far back you can easily go with things? Because, presumably, with PDFs, you don’t get back very far before the OCR and stuff was not that hot. Or are you re-OCRing stuff, or?
[Phil Gooch]: No, we don’t have an OCR engine at the moment. The PDFs do need to have extractable text. We did a project a few years ago with the British Medical Journal where we were just pulling out the end of article references from a collection of PDFs which were only scanned images. They did the OCR themselves, they sent them off to a company to do the OCR. We got the OCR versions of the PDFs back. And then we did all this extraction for them. And the data was really noisy, but at that time, we were just interested in getting the bibliography from each other. So the trouble is, we’re doing OCR on-demand, we often get people uploading 200, 300 page PDFs, and the idea of doing that on-demand just fills me with fear, having that run at scale. So we don’t do that. But, yeah. It could be done but that would be a separate standalone project, I think, that would be a research project to go and try to text mine that archive if you like old PDFs. And do something interesting.
[Mark Anderson]: The reason that it sticks in mind is it so there’s an almost implied temporal cliff somewhere, some distance back from us, where things start to come into easy digital focus. Which is unavoidable, but it’s perhaps something we need to start to recognise. Yeah so there was one other thought but it’s passed from mind, so I’ll let that be.
[Frode Hegland]: So, Phil. The reason you are here, as we’ve discussed before, is you allow for analysis, for interactivity. And I’m wondering, before, actually, I’m going to ask the question first, not to you, actually. Brandel and Fabien. I’m going to waffle on it for a minute now, but if you guys have something you want to show Phil that you have worked on or something else in VR, to help him see where this fits. I just want to highlight, for my own personal work, with my own personal software, when I look out and I see so many people doing amazing stuff, the only thing that I’m trying to contribute to is simplification. Because you can make things really horrendously complex, obviously. So I’m wondering if, maybe, by making interactions with this more tangible, we can have more… Yes, here we go. I can stop waffling now, Fabien would like to show something.
[Fabien Benetou]: Hey, everyone. So this is not actually a network analysis, graph analysis, or any Scientometrics. Simply putting the PDFs in space of an upcoming conference, it was for a VR conference. And then I think a lot of people got that struggle, a lot of people look interested, but then you have to start with one. I know, at least I can’t read two or ten papers at once, so I need to find which one. And basically what I do is, I put them in space, I set up the space to make it friendly or wanting with the conference. And then I’m going to put them, I have a little annotation system with a 3D object where I put a post-it note if I need to write something on it if I’m not sure if it’s interesting if it’s really mind-blowing and I want to read it first. And, yeah. That’s the result. It’s a social space, so I can invite somebody to go through and then we can discuss which one to read first. And then, at the bottom right, I don’t know if you can see clearly, there is a grey platform, and then I can send it to my ink reader and writer so that I can sketch on top and update it and all that. I have a couple of other examples where it’s more the graph view. And then you can go through it, but it’s a bit more abstract. So I think this was the more tangible way, and I would definitely like to have my personal annotation through this, for example. But I could very easily list to next to a paper or an article, information related to it. For example, scaling based on popularity or anything like this. Just a simple example.
[Phil Gooch]: That’s great. Yeah, that looks like a really nice way of navigating and picking out which sections you want to read, and papers you want to read. What I was looking at when you were showing that, just reminded me of a paper I saw years ago called document cards, which was one of the motivations for Scholarcy. Where they turn each paper into what they call ‘Top Trumps’. So, if you’ve got a lot of papers to visualise, it turns each paper into a single graphic that’s got the main image from the paper and maybe a couple of quotes from the paper. And it’s a way of showing everything on a paper in a single thumbnail. And maybe there’s a way of doing something like that, instead of showing those PDFs in your virtual reality, you’re showing, maybe, a condensed version of them, that maybe has just enough information to decide whether you want to read it or not, perhaps.
[Frode Hegland]: That's definitely worth us having a good look at just a little bit. Phil, on a sales pitch for the whole VR thing: How long ago has it been since you put on a headset? More than a year? Because, Phil, you must have done some VR at some point, right?.
[Phil Gooch]: I’ve not done anything. I might have put on a headset in a museum once or something, but…
[Frode Hegland]: Because the key thing is, it’s nothing like Second Life at all. And what Fabien was showing there is, once you're in that space, it becomes really useful and navigable. I sometimes write using Author, my own Author in VR. For the opposite reason that it’s normally good for because it means I have a limited field of view, I have a nice background, I have a decent size screen, the visual quality is good enough for writing, and it’s good enough for reading. You wouldn’t want to read forever. Sure, absolutely. But where the whole system is now is that we’ve done some experiments of a mural, and just having a single mural is absolutely amazing. Because it is really hard to describe, when that mural as an image, is on a computer screen, you kind of move it about, yes, of course, you can do that. But when you can have it huge and then you do a pinch gesture and it comes towards you and you zoom in different things, it’s kind of not explainable why it’s so special. And one of the reasons Ismail is here, we’re looking at doing some mural and timeline related to Egyptian history. It is really hard for us, we only started. I mean, Fabien and Brandel have been going for a long time, but the rest of us, we only started, basically in January. So I have my headset here, goes on and off depending on what we’re doing, but it’s really hard to explain the point of it. Because sitting down VR is one thing, but what really brought me over the edge was when Brandel said just moving your head a little bit as you naturally do, it changes everything. When we have meetings in VR, which we sometimes do, the sense of presence and being with other people, because the audio is spatialised, so if someone’s sitting there, the sound comes from there, it’s absolutely phenomenal.
So, I really think that Obsidian and all of that it’s nice, and even, as you saw in the beginning, Mark has taken, not even that many documents, but enough documents that that’s all the system can do, into this space, it quickly becomes messy. So, I think what you contribute is the ability to change the view rapidly and intelligently. There are so many interfaces for VR, and a lot of them is about using your hands, grabbing, and moving, and that’s all well and fine. But in some of them, you can have literally buttons to press for certain things to happen. So, I could easily imagine a document space, you start with one document, and at least in the beginning, you have a huge set of buttons underneath, very inelegant, obviously, that when you come across a citation, you can do what you already showed. They can start growing the trees. But all these buttons, again, initially can help you constrain and expand that view. It would be nice to have a spoken interface, it would be nice to pull, and that needs to be experimented with. But the reason I was so excited to have you here today was and is the real interactivity that you give. You take data that’s out there and you make it tangible in a whole new way.
So I hope that, what we’re trying to do, we’re trying to do some sort of a demo for the next Future of Text. We’re looking into building some work room. And Brandel has already taken, from Author, because Author documents are dots. They’re called dot Liquid, like, dot, dot, dot, Liquid. Inside them, we have JSON. So we have some of those goodies already. He’s been able to take the map view, with the relationships into VR. And, of course, it’s relatively static, but you can already touch things and see lines appear. To be able to go further, and to do, with what you have made available, would be really quite exciting. I mean, I could very well imagine doing the reading you’re talking about. You talked about making it fit on an iPad, but what about making it fit a whole room, right? Just putting one wall, to begin with. Where do you actually put the pictures? Where would you put the graphs? So many questions come up. It gets really interesting. It’s not very obvious at all. But thank you for allowing us to think with available data.
[Phil Gooch]: Thanks. Well, it was great to have the opportunity to chat with you all. Thanks for inviting me. I just wanted to touch on one thing that we spoke about in an email. Because at the time I had a hard time thinking what is the VR/AR angle on this. But you can imagine, in an augmented reality setting that you might have a book or a document in front of you, and you’ve got this augmented view that says, “Actually, here are the main people citing this paper. This is what they say about it. Here are the main findings of this paper” as a separate layer. So you’ve got the paper there you can read and navigate in this 3D space, and you’ve also got this layer that says “Hey, here’s the really important stuff in this paper that you need to know. And this is what other people are saying about it”. And maybe that’s one of the use cases for AR in this kind of idea. And as you know, Frode, the API is open, so if there’s anything that you want to add for your demo, just give me a shout and we can make it available to you.
[Frode Hegland]: I’ll go over to Brandel, but just really briefly, the thing about how things are connected in a VR space is really up for grabs at the moment. It really is the wild west. So one thing I think we need to do now is, just dream crazy dreams. For instance, the Egyptian opportunity, let’s say you have the mask of Tutankhamun sitting literally on your desk as you’re working on a project, you should then be able to say, “Show me how that relates to timeline, when it was found, and when it was used. Show me that geographically”. All these things should be able to come together. And right now, other than some idiot on Zoom, me, doing it with his hands, it doesn’t really connect. And I’m hoping that your, first of all, your parsing and your genius, but also your willingness to open your APIs to others, and to use other APIs can be a really powerful knowledge growing hub. And, yeah. Brandel, please?
[Brandel Zachernuk]: Thank you. Yeah, I definitely echo everything Frode is saying. If I can characterise what it is virtual reality, augmented reality, spatial computing at large does is that, when you have a display, be it a phone or a screen, even if it’s 30 inches or whatever that is, it’s still very much performs the function of a foveal vision. The central vision of what you’re looking at. And there was a lot of really neat exploration of the practical cognitive consequences that in the 1980s, where they’re saying, “It’s like browsing a newspaper through a hole the size of one column wide”. And what virtual reality does is take that filter away, so that you’re able to read those newspapers but you’re also able to see the whole space around it. And to that end, I think we, unfortunately, as a result of having 50-odd years of computing being the primary mode of interaction for at least some information knowledge workers, and certainly 30 years of it being in the absolute dominant form, is that we have surrendered the space that we would typically do information and knowledge work in, to a small computer with a very even smaller visual real estate. So we don’t have the ability to think about what the entire space is for, can be encoded for. And to that end, I feel like we have to go back to the metaphors that spring from understanding something like a kitchen or a workshop, where you have tools, they have places, when you’re standing in those places, when you’re gripping things in certain ways, that means you’re doing certain things. And that you might move a workpiece from one place to another in order to be able to undertake some kind of manipulation over it. And so, my hope is that, when people can return to that, within the context of knowledge work, where you can say, “I’m looking at this thing right now. But I have this stuff around me”. One of the things that I showed Frode and other folks in this group was being able to have writing that you’re doing here, and then having the word count over here. So you don’t have to click a button, open a menu in order to see that that information is available. Simply from something as simply reflexive as turning your head. Likewise with visual image search happening at the same time. But the other thing that this increased capacity for context does is that it increases, by orders of magnitude, the way in which scale can be used. If you think about a museum, in contrast to a book, or in contrast to an academic paper, which is even more compressive constrained, the way that type scale can be vastly changed in order to tell you things. Like, the exit signs and the titles over things are not just two times larger, but they’re maybe a hundred times larger. When you have a big piece of writing on a wall talking about how great (indistinct) is, they’re four different things but the sort of experiential consequences are absolutely legit. Because of the fact that you can devote that space to that, and this space to this. And so, yeah. I’m really excited about seeing all of the semantic information and insight that you have in Scholarcy, and really excited thinking about how to encode that into an entire space that people can manipulate and intervene on, at that scale.
[Phil Gooch]: Yeah, that would be awesome to be able to do that. Our API is open, so if people want to try doing that, integrating it into other systems they can do that. So, thank you. And also thanks for your suggestions about (indistinct) those entities. What type of thing are they? Are they a person? A place? And so on. Like you said, clicking on those links so you know where it’s going to take you in advance without having to wonder. Some great suggestions here, so thanks very much, Brandel. That’s great. I’m afraid I have to go. Lovely to meet you all. And, yeah. I’ll chat to you again soon. Hopefully at the next Future of Text.
[Frode Hegland]: Sorry I couldn’t see you on Thursday, Phil. But I’m presenting on semantics something that I don’t know anything about. But will be a fun presentation. All about Visual-Meta. Anyway, we’ll have coffee soon. Thanks for your time.
[Phil Gooch]: Take care. See you soon. Cheers. Bye-bye.
Post Presentation Dialogue
[Frode Hegland]: I was just going to say while he was still here but I’ll just say to you guys anyway. This obviously gives an opportunity to go from static documents to living dynamic knowledge object kinds of things. Imagine, have virtual bookshelves behind us and we can be writing a paper, one of our citations is refuted. Wouldn’t it be nice to be told that? Maybe that citation in our own document starts to pulse red and we have to pull it off the shelf and see what someone else does. Those are the kinds of opportunities we have. And in terms of the dreaming that we’re doing in the group now. I think, maybe, we should also try to dream about having absolutely all our knowledge in VR, not just one project at a time. Just a little thing. Because, as Doug said, "Dreaming is hard work." Fabien, I think you are next.
[Fabien Benetou]: Thanks. Again I think I mentioned it once or twice about why I’m doing going to free space. But it’s absolutely to have all my knowledge in here. Like 100%. So far, they’ve been a mix of me not knowing how to do it, the technology not being out there, not yet. Or again, a mix of both. But definitely. And also, the bridge between what I don’t know and what I already know. So that, I could, for example, go from one reference, things I have read, to another one, for example, that you suggested. So definitely what I wanted to show, also, before your remark was to criticise what I have shown. For example, you mentioned on the manipulation aspect, basically, and I think that’s the problem when I or others share images of VR, or VR content, people think, “Oh it’s another form of visualisation”. It’s absolutely not that. Visualisation can be part of it, but then, as you do the hand waving, that part is really fundamental. And being able to have a fast-paced interaction, tight feedback loop, being able to do it, again with a hand, relatively. Naturally it’s not perfect yet. But I think that’s the part that is really important. So I think always having gear for a short image to show that it’s not just like, they’re in space for the movement, the head movement also you describe. Having it in motion as a process. Ideally, also, have a green screen where we see the actual body of the person with a headset moving and grabbing the actual note, I think all that, especially for people who are not familiar, makes a huge difference. Of course, it’s a bit of work, having a studio set up and ready, so that everything is calibrated right for this. But for people who didn’t try it yet, they’re not the head thinking, “Oh, yeah. I understand”. They have no idea. So I think that also helps. Your product is still, of course, not good enough. And as you say, yeah, they need to try it. But I think that that’s like a little bit further still, so.
Frode Hegland: Yeah, I mean. Even if we have a virtual camera in the room, that doesn’t move. So that the virtual camera records from one perspective, and then you just see, yeah. Mark?
Mark Anderson: Yeah, because I (indistinct) that. That’s one thing I found myself just returning to do some more playing around with stuff in VR, was thinking that I know in principle how I could share that with people. But one of the things I find myself really wanting to do is, rather than write stuff down, is to essentially, for this state of the art to be probably streaming my first-person perspective of what I’m doing. Because I think what’s more important is to be able to… Because in that context, I’m not trying to convince someone they should use VR or not. But what I’d be trying to do is explain to people how things that some things that are hard that we thought weren’t. And you actually need to be seeing it through somebody’s eyes to do that. When I can’t turn my arm to this angle to do what I thought I could do, and so as I sometimes found. And an interesting thing, I found myself reflecting on thinking back on the notes I’ve been making about the processes. I can do this with my hand, it’s 180 degrees rotation, which is quite natural. But I found in some of the little puzzles and things I’ve been using to practice VR work, I was quite surprised, often I find I can only somehow, for some reason, it feels I can only turn it so far. They have to let go, get it again, and turn it again, which seems counterintuitive.
So I haven’t bottomed out quite what’s happening there. I wonder if it’s a cognitive blockage on this end or whether it’s something the way things move. And things like that I think are remarkably powerful to be able to show to someone as seen through your eyes, regardless of whether they’re in the VR or not. Simply because, otherwise, it’s very hard to explain. And the thing I set my hand up to say and I forgot about when we were talking to Phil earlier is that it strikes me, and they’re taking on board in a positive way the limitations of what we can do with some of our structural decomposition of text in terms of natural language processing and things. It says to me that one thing we can do, even as we mull over whether we are or aren’t going to move away from PDFs, would be to push towards more structured writing. So in a sense, in something like an academic publishing context, where there are some rules, I mean, to get published you have to obey some rules and I know some areas, I think in health and things have very much gone towards this. But there’s no reason to just not make that more explicit. And it doesn’t have to be everything. But even if it was just core things like abstracts, conclusions, or end pieces. Absolutely had to pass that, as you don’t get to go on the ride if you don’t do that. It’s not impossible to do. And it begs the question, for instance, if your conclusion is so vague and woolly that you can’t really break it down into something, in fact, maybe, you haven’t got any conclusions. Which goes back to the saying, “One of the joys of doing documentation is it teaches you how little you understand about the thing you thought you knew”.
[Frode Hegland]: We are recording (again). Would you like to pause a little bit, Fabien? And now let’s just pretend we’re talking and we’re going to continue in a second and no pausing is happening at all. And nothing important happened, over to you, Fabien.
[Fabien Benetou]: Yes. I think there is a big difference between having meta as a goal. Let’s say, using VR to analyse new ways to work in VR, versus bringing history back into the space. We start with being a room rule something else. Bob mentioned the idea of when he starts a mural, he has his own murals. He considers them. Maybe integrate part of them. And I think that’s very valuable. I personally have a wiki, every page of my wiki has a history, so I can go back at any point in time. And I have, I think I briefly mentioned to Brandel on Twitter today, that I have a personal obsession with phylogenies. I think the blank page doesn’t exist, it’s maybe a western conception. But overall, we always have something older that comes from. So I think bring some history, let’s say, if we do a VR room, we bring the Future of Text volumes. Or we bring whatever we want it. It’s not just interesting, but I think has to be done, is valuable. Still starting from, let’’s say, an empty space based on one target, one goal, for example, some points about global warming, but then, yes, bringing that history back in.
[Frode Hegland]: I think we’ve run over a lot. Just, yes. First of all, Jacob is working on exporting to HTML from Author. I don’t know exactly what that’ll be, in terms of what metadata will be how. I also I’m madly in love with all glossary-defined terms thing. And I think the reason I’m so in love with it is you probably, I know half of you will have this book, and you look at so many of the different diagrams. Things get messy so quickly. So if you have something, you decide yourself is things you really want to have in there, that that becomes very useful. And in the Future of Text books, of course, we also have a text timeline, history of text timeline. Which we can expand upon and import. So we do have some of that data to try things in as well. But, yeah. Okay. So, shall we try to dream a little bit for Friday? And then next Friday we dream? And then, but once we dream about, whatever, Egypt, or our own record, or climate change, or whatever it is. Then we decide, Okay, we settle on a topic, we settle on the beginning of a quote-unquote room. Is that kind of where we’re at?
Brandel Zachernuk: Yeah, that sounds pretty reasonable to me.
Frode Hegland: Very good. So, I wish you luck. I wish me luck. Dreaming is, I’ll say it again, it’s hard. Because it’s different from fantasy, obviously, right? Which is why I hate Harry Potter. Green flash, blue flash, no, no, the purple one is dangerous. Sorry, yeah. I gotta go. Okay. Thanks, everyone for today. Bye for now. Take care.
Frode Hegland: Augmented Work Room Thoughts
Thoughts on making a VR Augmented Work Room for the new Grand Egyptian Museum: Imagine being in your office or living room and putting on a head mounted display (HMD) and going to the Grand Egyptian Museum. You are standing in front of the Grand Egyptian Museum, rendered in beautiful detail. It is huge, just like in real life, and it’s a beautiful day. You step in to the virtual building, and you can walk around and enjoy the exhibits, even picking some up which are in reality protected behind glass. To really get to grips with the museum’s treasure of 18,000 objects however, you bring the items to what we call the ‘Augmented Work Room’, where you can really examine the collection. It’s important to note that the workroom is not owned by the museum, it is an open effort by the Future Text Lab to build a powerful work environment which in this case has a special connection to the museum, something we are working on how to enable for specific institutions to give the user a powerful work environment to learn, think, create and communicate. The room can have several scenes or layouts, which you can toggle between at any time. You enter with the Grand Egyptian Museum ‘scene’.
Timeline
The first thing you might notice in this room is the beautiful timeline mural on the wall in front of you. It spans thousands of years, from pre-dynastic to Ptolemaic, divided into layers, like a beautiful cake. Each layer representing an aspect of Egyptian history, such as rulers, building events, even weather and other events such as wars, famines and population sizes.
Although massive, you can’t help but see if you can interact with it and it turns out you can easily pinch to hold on to it and move it around, giving you effortless access to thousands of years of history. You realise you can fold it in ways to hide sections you are not interested in while looking at others and many other interactions give you a sense that you can really play with this timeline, in ways you could never have done with a printed timeline on paper.
When you are done, you simply pinch to hold the timeline and ‘throw’ (think of drag-&-drop on a traditional computer) it back against the wall, as though you dragged it onto the wall it was on initially and it snaps nicely into position. That was interesting so you pinch the timeline back towards you.
You and you speak “what can I do with this” and a voice answers you (knowing that you last interacted with the timeline and thus comments based on that) asking if you’d like a demo and you say yes and two hands appear, showing you how you can interact with the timeline. The voice continues, explaining how you the layers can be re-ordered as you see fit, and you can choose how tall they are simply by pulling them up, and then any layers you are not interested in you simply ‘throw’ to the ground and they become unobtrusive tin grey layers for you to expand again in the future should you so wish.
You are also shown how you can request further information for further layers, which can be almost anything that can fit a timeline, such as the position of the planets or stars, global population sizes and so on.
Your guide then explains how you can even tear off a section which you can then put into the traditional document you are working on, or place it somewhere in the room, along with other torn-off sections, so that you can see them in a different context. This is nice, but when your guide shows you how these torn of sections are still connected, then you start to see the real power of this environment. You can expand the torn off timeline in either direction, you can add notes to is (same as you can with the main timeline) and you can throw it back onto the main timeline and all your notes are included.
At this point you decide that you should probably start doing some work, after all, you are here to work on your university paper. You ask to have the room ‘reset’ and the room reverts to the state it was when you first entered. You look around and there are other elements in the room you have not paid attention to yet, including what looks like a diorama of the museum plus the pyramids and a traditional computer setup.
Academic & Scientific Documents
You go to the computer, which is already connected to your regular, ‘flatland’ computer so you can easily access your documents. You open a few of the papers you were reading and even though these documents are just PDF, they have useful metadata attached so you can have them open not as simply flat cards but as rich sculptures, based on how you are used to reading them in your own VR office space. The papers open in the sequence they were published in and their glossaries reveal what dates, places and items they discussed. You throw time onto to timeline and the timeline connects it to the correct spot, giving you a faint connection line. You then decide to have any thing with a date from any of the documents also illuminated so you speak connect all documents to timeline and a rainbow of lines appear, with colours coded based on you r earlier preference, which happens to map onto the layers in the timeline. Immediately you start seeing patterns and you keep working like this for a while, with the three initial documents but sometimes focusing on one to read deeply, then sometimes bringing in thousands of documents from relevant collections to see where their lines point.
Limitless, no data borders
You then bring your attention to the timeline again, which has now become a sculpture more than a rectangle.
This timeline is focused around the last few thousand years, but you can choose to go far beyond, even back to watching Africa collide with the Eurasian continent and you see Egypt itself come into existence and you can learn about how the sandstone which the pyramids are created from came about, all the way back to their subsea origins–and beyond.
And this point I’d like to point out that this Augmented Room is focused on the Grand Egyptian Museum but it is web powered and therefore you can expand in any direction to take advantage of a world of knowledge about any aspect, far beyond the curated museum, to give you context and insights no-one has seen or imagined before. You have the wisdom of the web and the interactions of time and space.
Step into the timeline
Having had enough intellectual stimulation for a bit you look at the timeline and see a few vertical slits. You point and ask “what is this” and your assistant answers: “Portals. Simply step through to experiment virtual worlds from that period in time”. You can also step into the timeline and enter an experience of Egypt like it was at the time you stepped into to the timeline. This is your first time doing this so you decide to enter the portal right by the building of the Great Pyramid and you enter a big budget game–at least it seems that way–where you can walk around a beautifully rendered and accurate scene of the building of the pyramid. This is based on a game engine so you can interact with the world and even speak with the inhabitants.
These experiences have been created by game designers and are richly textured. This is a time travel Metaverse. These experiences have been designed to give you a feel for what the periods of time were like, but many of the items you come across are in the museum and therefore you can learn more about them on the spot to bring them into the Augmented Room, where you can examine them, which is what you do. The item you have taken back is a small piece of jewellery but you can interact with it in whatever size you want to and you can choose to show or hide the museum’s tags, which in this case includes the composition of the piece, which includes gemstones not found naturally in Egypt.
Diorama table / Map
You then pause and look at the large table with a model of the museum and the pyramids of Giza.
You wonder if you can interact with this also, so you try to use your hands to gesture that the map should enlarge and so it does, you can now choose to go inside the pyramids. This is amazing but what about the other way? Yes, you can make the pyramids smaller and smaller, until you see all of Cairo. You hear a voice suggest–this is from your subtle digital guide, whom you have paid little attention to so far–that you can choose to move the timeline and see the time change on the map, it is linked. You do this and then you see a thread on the timeline for the buildings of the pyramids so you touch them and see the map move through time to the pyramids construction and since you tapped on a specific point in the timeline you will see an animation of the first pyramid being built.
Then you remind yourself of why you turned to look at the map and you take the tag with the list of compositions of the jewel and throw it onto the map, which then shows lines to the origins of the materials, if there are only one or two options and a note appears next to the material which is universally available asking if you really want a hundred thousand lines. You tap ‘no’. The elements have come from far and near and this is relevant of your work so you take a ‘snapshot’ of the map, open your own paper and paste it in there. When someone reads your paper using traditional means (PDF in flatland) they will have the data, but when someone reads it in VR, they will be able to recreate this view.
You then tidy up your workspace a little since there items and lines all over the place but as you do so you decide against spending a lot of time tidying so you simply bring up your virtual wrist controller and choose to ‘freeze room’ and the layout is saved for you, tagged by the time and date, as well as the items in the room, the timeline range on display, the documents you were reading and what document you are authoring, so that you can use any of those ‘hooks’ in your memory to open up the room to this layout again, should you wish.
At this point you are interrupted by a friend who enters the same Augmented Room and you excitedly show your findings, which you both then discuss and put into a multimedia, multidimensional presentation of the timeline, the map and a myriad of academic papers, take your HMD off and send the presentation to a colleague who can access all this data, in the same environment or any other web compatible environment since this is all open data, shared to augment the world’s understanding of the rich heritage of Egypt.
From pure fantasy to achievable dream
To make this possible we need to develop the means to introduce many types of data into an environment, via the web, including many we as designers have not thought of, how to show it and how to hide it. We need to develop the means for information to be able to be thrown or drag-and-dropped to connect. We will need to experiment with interactions and we will need to look at how best to store information in robust ways, in VR while authoring and to take it out, as richly as possible into traditional media.
And of course, we’d need to talk to games developers about the game-like experiences and how items could be moved between rooms/realms/software.
Furthermore, the idea of spaces will have to be examined and, as Adam says, what is free and what comes at a cost in such a world. We’d need to work on data infrastructures and interactions simultaneously. Can we do anything like this?
Coda
This is simply a dream piece, but it needs to be emphasised that the dream is not to build something like this as a stand alone app. The core of what we do is to work to support and open environment and therefore this will need to be built on Web technologies.
Frode Hegland: Deep Dreaming
We agreed to try to dream this week. I am not sure how to go about that directly, so I think I’ll try a stream of consciousness walk, with a rough time horizon being 5-10 years in the future. This walk starts by putting on a near-future set of goggles/HMD’s/visors† and initially all I see is the room I was in–my real room is my lobby. This room was scanned at the point of putting on my visor, so the room is not shown as pass-through, but as fully rendered 3D room overlay. People appear as video however. Anyway, all of these are decisions I have previously made for what I want to see when I enter VR (I really, really don’t like the term ‘Metaverse’ both because it is now partly ‘owned’ by Meta, through the trick of Meta naming itself after the Metaverse and I also am not focused on the social side, which is what the Metaverse term now owns). The work I need to do is to do some writing and edit a special edition of The Future of Text, based primarily on our article journals.
Focused writing (pretty much as now)
A small view brings benefits in this mode. For some reason, even though I have a fantastic quality visor, when I need to focus I prefer to write on a screen similar to my laptop, at a similar location, perhaps a little higher off the table, since I prefer the keyboard being closer to what I type. I also have problems focusing or getting into flow often, I am not one of those people who likes a lot of blue daylight to work in. So I dim the room and turn on artificial warm light which fades to darkness towards my periphery. This lets me focus and people still ‘pass through’† so I don’t feel exposed or unaware. Since objects are rendered and understood I can even effortlessly reach for my coffee when I so wish, with no spillage fear beyond what I would normally have in ‘normal’ world.
Editing (far beyond now)
There are real challenges to how text elements can be spread out and used, even in 2D. I look at how I am writing this in Author today and it’s not easy. I wish I had some way to make it all more visual and that I could expand and collapse easily and move chunks around. One thing I really want to be able to do is to fold individual sections by clicking on the headings and hiding all that’s below that heading†. Formatting by breaks† quickly becomes large. I will also try bolding which is nice in Author because cmd-shift-b greys out everything which is not bold. However, what is the test way I can encapsulate thoughts in ways which gives me a good overview?
Journal reading
After a while of working on my laptop and running out of what to write, I decide I need inspiration and since I am writing a report on what we are doing in our FTL community, and since we have a full record of all our meetings and Journal editions, I decide to flip through our dialogue record. I decide I want to work on a space the size of my dining/work table so I open/summon all the issues of our Journal. They appear as a documents floating in the air, there are quite a few of them and they look nice, but it’s a bit much.
I move my palm face up and options appear which I use to see all the authors of articles. The options I get in here depends on what the metadata has available and of course we have Visual-Meta with this information. I then choose to have them sorted by when they first write something, which I find less useful. I then get all the glossary terms† with the most used ones larger than the rest. I tap on a few with my fingers to see lines to the articles they appear in and the authors who used them. After doing this for a bit a I can see that a few authors focused on a specific topic, which makes sense. I then choose one term and command to see all the usages, as lines floating in the air, with lines to author names and Journals when I tap them. How this can be done, I don’t know, specifying what will be shown will be a serious part of our research I expect. I personally feel it should feel more like sculpting with clay, or even lego bricks, than programming, but for those who are adept at programming they should be able to use their skills as well.
Paper to VR to desktop
I have just finished Metazoa (Godfrey-Smith, 2020), which I read on paper, and I decide now is a time to summarise it for an article in the Journal, so I pick up my paper copy and thumb through it, allowing my high-resolution visor camera to read the text on the pages I view, including what I have underlined or otherwise scribbled on/annotated and bits I double-tap point to as being important. I make a motion as though I am about to throw the book into the air and this is interpreted as an action to open all the pages of the book in front of me, in a curved horizontal stack of pages. I put the physical copy down.
I can easily gesture to flip though the pages, pull out pages of interest and so on. It’s oddly satisfying. Below this list, if I turn my palm face up, a list of options appear. I choose to see only paragraphs with annotations. Some which I decide are not relevant I flip away. The rest I keep and use both hands to funnel into my document.
These annotated paragraphs appear as quote paragraphs in my document on my laptop. In this world all my digital media know about each other, the VR Cyberspace is just seen as the more complete/real version. Anyway, these paragraphs are taken as chunks by my word processor† so I can easily move them around and add my commentary as I see fit. Having completed this article I feel it’s a bit flat so I clear my virtual area where the rest of the book is (I simply wave the pages away) and gesture for this article to float above the laptop. Here I put the quotes in what looks to me like a good order, including a few relevant connecting lines, some highlighting and even a few illustrations from the book which I reach across to grab from the now-folded book on my right (after I waved it shut).
When I export to PDF (yes, PDF!), a reader can choose to gesture to have that article, or the whole document, opened into their VR space and unless they have specific preferences, the layout I just made will be how they appear initially.
Glossary terms
The book used a few terms which I had not included in the Defined Glossary so I select them and do cmd-d on my keyboard, same as I can do today. I still prefer to use the keyboard for some interactions since it’s fast and does not require me to point in space or speak while thinking. I leave the book’s own description of the terms and the definition includes a reference to where it came from†. What is also interesting is that the Define Glossary Dialogue, which is floating slightly off the page, it’s not flat as on my laptop, shows lines extending to my bookshelves (I have more than one, not sure how they are organised though, at this point) and into the horizon, indicating that there are connections to books (in one direction) and papers (in another direction) which I have not read yet but which I might consider. They are deemed relevant because of what I have in my library and what my colleagues and friends rate highly.
Please have a look at my document on proposed Glossary Upgrades for more on this.
Live analysis
I pull on one of these sets of lines and I can see what the link to. I have insanely powerful analytical engines so to speak, on tap, such as Scholarcy, so there is real semantic meaning in the connections. I see one book which looks interesting and pull it towards me. This book looks very interesting indeed so I order it to be delivered on paper and read it and annotate much like Metazoa.
In between working on different articles in our Journal the document starts to glow red and I see, when I turn the document over to look at its virtual cover which features metadata, that a citation used in the document is now in doubt, since the citation has been refuted by other papers. I’m grateful for this and follow the threads and agree, and decide to update the citation.
Real life, 360 meetings
Much like I like to read on paper and digital, I also like to have meetings in non-VR when it’s possible. Some of these are captured by my little 360 camera, which does a decent job with visual quality and 3D element extraction, as well as spatial audio. I have recently started experimenting with using 3 such cameras, placed around the space, to have a very high resolution capture of the meeting or event and I feel this gives me a more pleasant experience watching it later. Nothing work-related for me watching some of this today, it’s family events from when my son was younger.
Timeline
Back to work. I stretch a timeline in front of me and zoom and push and pull and change what is shown, in a, to be honest, fun way, I then step into a section on the timeline which has a portal and I am presented with a few options, from architectural exploration to simple games, which are explicitly set in that timeline or something close. Stepping into the timeline is connected to a VR App Store so the choice is pretty good but not always accurate, so I need to decide if it’s for fun or work, and if it’s for work I go to a vendor I trust. One of my favourite experiences is to go back in time and hear (recreations) of influential thinkers or authors read their own work. I just enjoy it.
Connection to outside
For a moment I had forgotten that, although I am listening to deep trance music to help me concentrate, I have left an audio channel open to my wife, who asks me a question. She is on her Apple Watch, not in VR, but I can hear her perfectly well. Because she is with our son at an event I could not attend today, she takes out her own 360 camera† and streams the event to me. Even though she is hand holding it, the image does not move for me, it is stable and beautiful, if perhaps a little less impressive than what the model I own can do, but then again, my model does not stream as well. There will always be different levels of features for devices I guess.
That’s enough for one day, I take my visor off and start making dinner which I enjoy with the family and my wife and I enjoy Hamilton on the big screen in the living room for the 400th time. It only ever gets better.
Day 2
The next day I decide I want to really build guided tours of our Journal. We have quite a few year’s worth of content after all, so I move my physical desk over to the side of the room† and put my visor on, which instantly re-maps the room.
Voice Commands
For fun, I decide to use voice commands today and, since the visor knows I am alone, I can speak commands without a preamble. ‘Show me all Journal entries’ I say. They appear nicely in front of me†. I then say ‘show me a list of authors’ and this gives me a column of names of authors in the documents, which I place where I want. I could have tapped on the metadata icon on the document and chosen this, plus ‘for all documents’ to do the same.
I am going to make a 10th anniversary ‘The Future of Text’ volume out of this, in collaboration with my colleagues, so I need to present my edit of the book for discussion.
Further Glossary
I see a name I have not seen in a while in the author list and tap on it. I get a halo of options and I choose to search the web for the name, where I learn that this person is doing interesting work at the moment. I copy what I found and put it in the Defined Glossary entry for that person. With that person’s glossary entry in my hand I say ‘hide everything else’ (where everything else is taken as meaning everything else than what I give explicit attention to by holding) and then ‘show all connected glossary terms†.
I now have the beginning of a visual Map of how the Defined Glossary terms are connected†.
I import Glossaries from previous Journal issues and it gets rich but a but messy. I then spend some time on specific layouts, with annotations and folded sections, and save these layouts. I can always come back to these layouts and I can link to them from the text, same as I can link to an image or a heading, so that I can show the reader specifically what I mean on the Map.
Recorded walkthrough/presentation
I decide to make what I have found into a VR ‘article’ so I speak ‘record’ and I say I noticed this person is doing something, and I gesture around the Map and the system records everything. When I say ‘stop recording’ it stops recording before I speak ‘stop recording’.
I then say ‘use my official voice’ and it changes my voice to my own, but one which has been recorded when I was focused on presentation, much like using someone else’s voice.
This can now be shared and viewed by anyone. It can also be added to the document itself, as a link to a guided tour by the author.
Collaboration
I then email this to my colleagues who receives this in the format of a 2D video, but with steganography to allow a VR viewer to play it in 3D VR. The title of the email is a smart sentence constructed based on what I said and it also has a beautiful 2D image ‘screenshot’. One of the replies I get within minutes is simply the voice of a colleague saying “OK, let’s have a look at this” and based on this I invite the person in. The person appears as a fully rendered face but body greyed a bit and semi translucent so I guess she is sitting or fidgeting or something and only want to share head-attention, and hands when needed. We go though the Map of the defined Glossary and have fun looking at relationships. This is an area of interest for me even now, since I believe that defining key concepts helps both author and reader understand.
App rooms
There are also dedicated rooms for specific VR interactions I sometimes use, which I call simply ‘App rooms’ now, since they are sold as VR apps. I sometimes use one with my son since he is interested in space travel and planets, so we hop around the solar system together. I also use it to check out neighbourhoods in Google Earth VR and so on.
Reflections
Even at this point I must pause and wonder how I am going to write this with my current tools. I have started as a kind of stream of consciousness and then I go back and edit for flow and add new thoughts. But this becomes a bit jumbled, I am not writing about the Glossary in only one location for example. Furthermore the question of how to manipulate a large amount of text based information in VR becomes more and more relevant. Many of the other issues I’m pretty sure others are working on, as parts of the Metaverse, such as meetings and maps and so on.
Single document interactions (single frame)
There is so much polish still needed in Author for interactions† and there will be plenty polishing in VR. However, this is no reason not to get started, it is just a note to remind us how much polishing will be needed.
We will likely need more than one way to accomplish the same things, at least for some of the more general interactions. Such as:
The options themselves will beed to be clearly defined and might benefit from implementation in 2D first. For example, show only Names, works in Author and cmd-shift-n is a good interaction for the basically trained user. This would easily fit in a control panel and maybe even work in voice. A lot of this can be done in traditional ways. A lot of this relies on metadata being present so that systems can know what is what. We should not ignore that.
Twitter Workgroup Discussions /Highlights
Room Based VR?
Adam Wern
Room based VR, or not room based VR, that's the question. Walls, colors and forms are free – but are they needed? Are the rooms needed? Is the outer world needed? It feels like nested Matryoshka dolls here – do we embrace that nestedness? Or do we go minimal, floating objects, perhaps with just a sense of up and down, in the abstract? Or mixed metaphors for different things?

lovely colors at the Cooper Hewitt Museum!. Freiberg, 2022.
Also interfaces where the walls come to you:
On the other hand, hyper-textual walls that appear, disappear, shrink and grow, etc can live in a hyperbolic space where we instead provide sensory landmarks for the Path to them, not their absolute Position.
Fabien Benetou: Preparing my own triage of proceedings from #IEEEVR2020
Fabien showed this screenshot as an early example of academic documents in a VR space:
what paper will I read next?!. Benetou, 2022.
What if you wanted to annotate your in #VR research triage? (cf earlier https://twitter.com/utopiah/status/1242090502775877632… )
With some custom space on what to actually read then eventually write (or implement as @AFrameVR plugin for @MozillaHubs)
With Spoke you can have spawnable elements for @MozillaHubs for example… post-it notes! You can in fact how your entire palette of visual annotations and have a little doc
I drag the PNG cover of the PDF use drag&drop on desktop then I pin in order to make it permanent so that I can re-enter and have permanence.
Details on https://t.co/2fvSLCwKKw if you want to setup a similar space. 
For pining on desktop you highlight the target object then press space.. Benetou, 2022.
Resources
“The Extended Mind: The Power of Thinking Outside the Brain”
Book by Annie Murphy Paul
As recommended to the group by Brandel and enthusiastically re-recommended to many by Frode and others:

The Extended Mind: The Power of Thinking Outside the Brain. Murphy Paul, 2021.
NVIDIA Research Turns 2D Photos Into 3D Scenes in the Blink of an AI
Tech, presented by Isha Salian
This gives an indiction of how amazing real-world images can enter VR with only basic reference materials:

Instant NeRF. Anon, 2022.
“Instant NeRF is a neural rendering model that learns a high-resolution 3D scene in seconds — and can render images of that scene in a few milliseconds. When the first instant photo was taken 75 years ago with a Polaroid camera, it was groundbreaking to rapidly capture the 3D world in a realistic 2D image. Today, AI researchers are working on the opposite: turning a collection of still images into a digital 3D scene in a matter of seconds. Known as inverse rendering, the process uses AI to approximate how light behaves in the real world, enabling researchers to reconstruct a 3D scene from a handful of 2D images taken at different angles. The NVIDIA Research team has developed an approach that accomplishes this task almost instantly — making it one of the first models of its kind to combine ultra-fast neural network training and rapid rendering. NVIDIA applied this approach to a popular new technology called neural radiance fields, or NeRF. The result, dubbed Instant NeRF, is the fastest NeRF technique to date, achieving more than 1,000x speedups in some cases.”
https://blogs.nvidia.com/blog/2022/03/25/instant-nerf-research-3d-ai/
ShapesXR
VR Collaboration tool
Impressive VR collaboration tool for teams building environments: “VR Creation and Collaboration Platform for Remote Teams”
https://www.shapesxr.com

ShapesXR. Anon, 2022.
Scomis conference video
Conference Proceedings via Peter Wasilko
Peter Wasilko: “The Scomis conference video is now up. I highly commend Zoe Scaman's Keynote at time index 13:56 which covers Hamilton and Assassin's Creeds VR Simulation of Ancient Egypt as well as TickTok for book reviews.”
https://scomis.silverstream.tv/view/1

Scomis Live. Anon, 2022.
The Under Presents
VR experience via Brandel Zachernuk
Adam, the session at the Game Developers Conference from "The Under Presents" were right in line with your interests – it's a semi-scripted, partially improvisational VR cabaret space:https://tenderclaws.com/theunderpresents

The Under Presents. Anon, 2022.
They pay actors to perform and interact with the audience, which is a fabulous opportunity to play with the idea of a 'scripted environment'. I really like the idea of just using people performing (some occasionally non-anthropomorphic) roles in facilitating experiences for other people.
It was also suggestive of a better solution than the largely hollow "play to earn" mechanics that are being offered as a way to entice people to be part of a game world – when participants can provide actual value to other people, there's an actual service they provide. Being able to role-play as an NPC in a game might not be as fun as being the heroic player, but it would be interesting to look at what could be on offer as a set of mechanics to them if it was cheaper or understood to be otherwise compensating players.
Anyway – really interesting both from a prototyping perspective – once you have an XR copresent environment, having interaction facilitated by a docent rather than programming it all (or programming for the benefit of a docent to pull the strings more unobtrusively)
And from a perspective of keeping people in the loop permanently and seeing XR as being primarily a human-to-human mediation system rather than an interface _to_ a computer, the way it's typically presented.
Adam Wern:
Brandel, Thanks for that link! 100% my interests 🙂 And this human-to-human perspective is really interesting. Recorded guides vs co-present guided tours – imagine a weekly tour for a virtual knowledge object instead of an old building. Or live creation vs timelapses. Or even livestreams of people just studying.
And all this reminds me Neal Stephenson's "The Diamond Age", a book that I often think about. Featuring an e-book that has co-presence with facilitators (actors in VR).
Also relates how we create knowledge objects to socialise around (Knorr-Cetina, 1997). And how we identify with knowledge objects. Like our group (FoT): ~ we care about Text, VR, Learning etc and identify as Text-people (in some sense) and socialise through it. Perhaps that is even the primary function of the group.
Oh, the creators of "The Under Presents" were inspired by Diamond Age it seems! Will try it on Oculus as soon as possible. 
Brandel Zachernuk:
The idea that an e-book (or 3d hypermedia artefact) could come with a recorded, and occasional live, tour is very interesting. Or the VR Bookclub, where we drop recordings & notes along the way of our reading for our friends to read.
I like the idea of a vr book club as an evolving space integrating the book and discussion of it – either direct passages bearing reference to positions in the text or thematic discussion more diffusely related to stuff scattered throughout.
Adam Wern:
The book as the ground, with discussions growing like flowers from the text .
Putting two book clubs (for the same book) side by side, as corridors.
Virtual Design Workspace
Research paper and video via Fabien Benetou
Joshua McVeigh-Schultz: “The research involved fieldwork with VR designers and industrial designers. The insights we gathered helped inspire a series of VR experiments that explored new interfaces and workflows for creative collaboration.”
http://joshuamcveighschultz.com/virtual-design-workspace/

Virtual Design Workspace. McVeigh-Schultz, 2017.
“What Is It Like to Be a Bat?”
Academic Paper via Fabien Benetou
‘What Is It Like to Be a Bat?’ is a paper by American philosopher Thomas Nagel, first published in The Philosophical Review in October 1974, and later in Nagel's Mortal Questions (1979). Fabien Benetou asks: Maybe that's a bit far fetched… but maybe not. It's a truly different experience so explaining might just not be good enough.

{kind=link}
Big eared townsend bat (Corynorhinus townsendii). Anon, 2002.
Brandel Zachernuk:
Probably only peripherally related but I really like Dennett’s response to Nagel, “What it is like to be a bat”: “Twenty years ago, Thomas Nagel presented a talk at the Chapel Hill Colloquium entitled “What is it like to be a bat?”. I commented on it, with a response entitled “What is it like for there to be something it is like to be something?” In it I tried to show what was wrong with his central claim. He didn’t believe me, and I guess it’s just as well, for he went on to publish the paper, in Phil. Review, 1974, and it has become perhaps the most famous and influential paper in the philosophy of mind, widely known outside of philosophical circles. I may have had something to do with the spread of its fame, since ten years ago, in The Mind’s I, Doug Hofstadter and I reprinted Nagel’s paper, along with some reflections, mainly by Hofstadter, which went a lot further (we thought) to show what was wrong with it. ”
https://ase.tufts.edu/cogstud/dennett/papers/what_is_it_like_to_be_a_bat.pdf
Document Cards: A Top Trumps Visualization for Documents
Academic Paper via Phil Gooch
The Document Card pipeline. Strobelt, Oelke, Rohrdantz, Stoffel, Keim, Deussen, 2022.
Abstract— “Finding suitable, less space consuming views for a document’s main content is crucial to provide convenient access to large document collections on display devices of different size. We present a novel compact visualization which represents the document’s key semantic as a mixture of images and important key terms, similar to cards in a top trumps game. The key terms are extracted using an advanced text mining approach based on a fully automatic document structure extraction. The images and their captions are extracted using a graphical heuristic and the captions are used for a semi-semantic image weighting. Furthermore, we use the image color histogram for classification and show at least one representative from each non-empty image class. The approach is demonstrated for the IEEE InfoVis publications of a complete year. The method can easily be applied to other publication collections and sets of documents which contain images.”
https://bib.dbvis.de/uploadedFiles/29.pdf
Visualizing Wikipedia as a tree in VR
VR via Fabien Benetou
Just an experiment to research UI/UX for tree structures in VR.

github. Marinmiro, 2019.
You can read more about it here:
https://medium.com/@oscarmarinmiro/https-medium-com-oscarmarinmiro-visualising-wikipedia-articles-in-xr-4b1b1164a780
Live demo at https://oscarmarinmiro.github.io/wikiTree/
Data is taken from Wikipedia 'vital articles': https://en.wikipedia.org/wiki/Wikipedia:Vital_articles/Level/4. In bin/ you'll find a Python script using Beautiful Soup to generate the data
In www/ there's a parcel build system for an interactive VR demo, using AFrame+AFrame components and D3.
Colophon
Published March 2022. All articles are © Copyright of their respective authors. This collected work is © Copyright ‘Future Text Publishing’ and Frode Alexander Hegland. The PDF is made available at no cost and the printed book is available from ‘Future Text Publishing’ (futuretextpublishing.com) a trading name of ‘The Augmented Text Company LTD, UK. This work is freely available digitally, permitting any users to read, download, copy, distribute, print, search, or link to the full texts of these articles, crawl them for indexing, pass them as data to software, or use them for any other lawful purpose, without financial, legal, or technical barriers other than those inseparable from gaining access to the internet itself. The only constraint on reproduction and distribution, and the only role for copyright in this domain, should be to give authors control over the integrity of their work and the right to be properly acknowledged and cited.
1 thought on “1.3”